Most of our clients (Agile software teams) use Atlassian Jira for managing tickets and sprints. Every day, we keep updating the Jira for all tasks that are being worked upon. We realized that Jira has huge project/team data logs but Jira reports were not that helpful in capturing work habits of teams. Hence, Qxf2 has ended up developing an ‘Engineering Benchmarks’ web application using Python and Flask to generate different engineering metrics based on Jira data. These metrics help our engineering teams in identifying internal problems and track their progress.
Why this post?
We got tired of hearing developers say “QA is the bottleneck”. As experienced QA, we suspected the problem really was twofold:
a) poor work habits of developers, E.g.: tickets arriving in a bunch at the end of the sprint.
b) wait times seem longer than they are, E.g.: developers rarely realize how long they spend on a ticket!
But there was no easy way to prove our hypotheses. JIRA reports did not help and asking people to track their time seemed to be a very costly and error-prone option. So, out of sheer frustration, we ended up building Python scripts to measure two things:
1. How long a ticket spent in different states?
2. Timeline in which JIRA tickets arrived at a particular state (immediately exposes bursty behavior!)
Since then, we have used this code to figure out a lot more work habits like poorly commented tickets, how often pairs of people collaborate over JIRA, etc. Internally, we call this project ‘engineering benchmarks’. We thought of sharing the details of our engineering benchmarks application development and few engineering metrics as well to help other engineering teams who like to create their own Jira metrics with graphs.
What is in this post?
In this post, I will share the details of two Python modules Qxf2 wrote and feel would be useful to all the teams starting out on a similar exercise. I will be going through the details about one of the important back-end modules called ConnectJira which contains wrappers for all the Jira related API calls and the JiraDatastore module which saves ticket information.
The ConnectJira module
This module provides wrappers around Jira’s REST API. We are limiting the code snippets to list only some of the most frequently used calls in our analysis. You can see the entire code for ConnectJira.py in this GitHub gist. For your convenience, we will help you get setup and explain a few of the methods we ended up using quite a lot in our analysis.
a. Install jira-python through pip
You can install the jira Python module by running the below command on your command prompt:
$ pip install jira |
To test if your install worked, pull up a Python interpreter and try the below lines:
from jira import JIRA from jira import JIRAError |
If your install worked, you should not see any import error.
b. Interact with Jira client using an instance of this module
You can create a Jira client easily:
connect_jira_obj = ConnectJira(JIRA_URL, USERNAME, PASSWORD, PROJECT) |
You can access any connection error details by using the connect_jira_obj.error.
c. Get Jira ticket list
Fetching the result of a JQL is one of the most common operations you will perform:
jql = "project=%s"%project connect_jira_obj.execute_query(jql) return {'ticket_list': ticket_list,'error': error} |
Parameters: jql, Return type: dict
The returned Jira ticket list data view will look something like this:

d. Get jira ticket in json with changelog expanded and selected
If you ever want to dig into the history of a ticket (e.g.: how often did it enter the ‘in testing’ state), you will need to become friends with a ticket’s changelog. Here is how you can fetch a ticket with its complete changelog.
connect_jira_obj.get_ticket_in_json(ticket) return {'ticket': ticket_expanded, 'error': error} |
Parameters: Ticket key, Return type: dict
The returned json format ticket data view using (thanks JSON formatter!) will look like this:
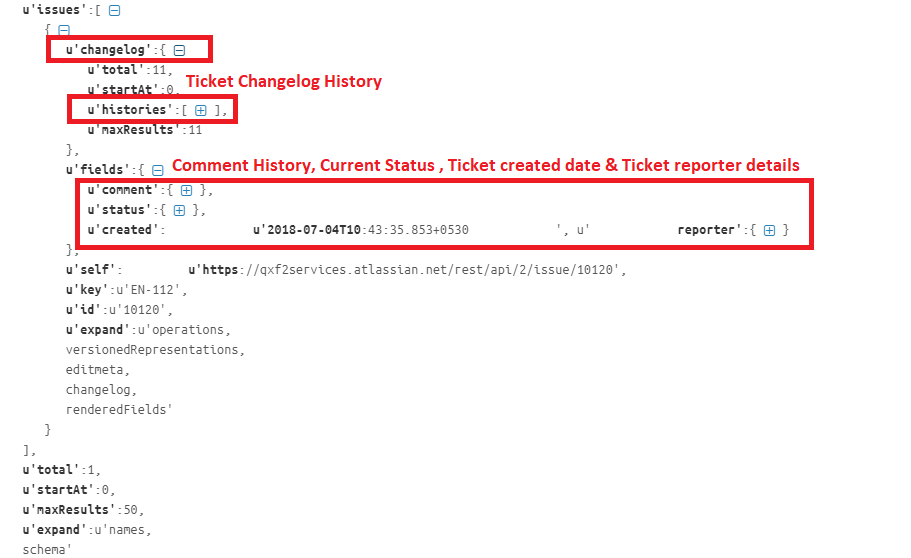
e.Get the Jira workflow statuses
Sometimes, you will want to know all the statuses that are present in a Jira instance. You can do that like this:
connect_jira_obj.get_statuses_from_jira() return {'statuses':statuses, 'error':error} |
No Parameters, Return type:dict
The returned data looks something like this:
{'statuses': [u'open', u'reopened', u'closed', u'to do', u'in dev', u'code review', u'ready for test', u'in test', u'peer review', u'reopen', u'integration test'], 'error': None} |
f. Get the list of Jira boards that are associated with the project
Fetching sprint boards to analyze is useful too:
connect_jira_obj.get_jira_project_boards(jira_project) jira_project_boards = [{'id':board.id,'name':board.name}] return {'jira_project_boards':jira_project_boards,'error':error} |
Parameter: jira project name or Id , Return type:dict
The returned list of jira boards looks something like this:
[JIRA Board: name=u'EN board', id=1, JIRA Board: name=u'QTR board', id=3, JIRA Board: name=u'TDP board', id=2] |
g. Get the list of Jira sprint ids for the given Jira boards
Sometimes we want to analyze metrics on a sprint by sprint basis:
connect_jira_obj.get_jira_project_sprints(jira_project_boards) return {'jira_project_sprints':jira_project_sprints,'error':error} |
Parameter: list of the jira project boards, Return type:dict
You will see the returned list of Jira sprint ids

h. Get ticket list for the given sprint id
connect_jira_obj.get_sprint_ticket_list(sprint_id) return {'sprint_ticket_list':sprint_ticket_list,'error':error} |
Parameter: sprint id, Return type:dict
i. Get sprint details for the given sprint id
connect_jira_obj.get_sprint_details(sprint_id) return {'sprint_details':sprint_details, 'error':error} |
Parameter: sprint id, Return type:dict
Returned sprint_details data view
{'sprint_details': JIRA Sprint: name=u'EN Sprint 1', id=1, 'error': None} |
Storing Jira Tickets
We found it is useful to fetch and save individual tickets as pickled files. That way, we only needed to update our datastore with recently changed tickets rather than fetching all the tickets we were analyzing over a timeframe. All Jira tickets are stored using Python pickle. Here are some of the useful methods we ended up writing and a short write up of how updating the datastore works.
Note: You can see the entire code for JiraDatastore.py in this GitHub gist.
1. Update datastore will be run based on the last updated date stored in pickle
jql = "project = '%s' AND updatedDate >= '%s' ORDER BY updated DESC" % (self.project, last_updated_date) jql_result = self.connect_jira_obj.execute_query(jql) ticket_list = jql_result['ticket_list'] self.store_ticket_list(ticket_list) |
2. If datastore does not exist already for the given Jira client and project, we run complete datastore for the given project
jql = "project='%s' ORDER BY updated DESC" % (self.project) jql_result = self.connect_jira_obj.execute_query(jql) ticket_list = jql_result['ticket_list'] self.store_ticket_list(ticket_list) |
3. We make sure to run update_datastore in the backend code before fetching tickets from our pickle db to generate metrics for the up-to-date Jira data
self.datastore_obj.update_datastore() |
You can have a look at thorough details of some interesting engineering metrics that we have created in the following blogs. Feel free to write to us if you like to create engineering team Jira metrics.
NOTE: While Qxf2 has the habit of open sourcing many of our R&D projects, we will not be open sourcing this code in the near future.
I have around 10 years of experience in QA , working at USA for about 3 years with different clients directly as onsite coordinator added great experience to my QA career . It was great opportunity to work with reputed clients like E*Trade financial services , Bank of Newyork Mellon , Key Bank , Thomson Reuters & Pascal metrics.
Besides to experience in functional/automation/performance/API & Database testing with good understanding on QA tools, process and methodologies, working as a QA helped me gaining domain experience in trading , banking & investments and health care.
My prior experience is with large companies like cognizant & HCL as a QA lead. I’m glad chose to work for start up because of learning curve ,flat structure that gives freedom to closely work with higher level management and an opportunity to see higher level management thinking patterns and work culture .
My strengths are analysis, have keen eye for attention to details & very fast learner . On a personal note my hobbies are listening to music , organic farming and taking care of cats & dogs.


This is a great work! I wish it was in Python 3. Do you , by any chance, have the Python 3 version of this?
Hi Mahshid,
We do not have Python 3 version of this program.
Thanks,
Nilaya