As a part of Qxf2Services Hackathon, I had picked up a project to automate testing of a readily available Text to Speech web app. To follow along, I assume you have some familiarity with Python, Selenium.
Overview of Text to Speech Demo app
To try out the testing of Text to Speech, I was looking for a readily available web app which can help me achieve my goal. After some googling, I found out a readily available and hosted Text to Speech Demo Web app. This Text to Speech service understands text and natural language to generate synthesized audio output complete with appropriate cadence and intonation.
Working of Text to Speech Demo app
To use Text to Speech Demo app user needs to :
- select the voice language of his choice from the dropdown
- Input the text (Note that The text language must match the selected voice language)
- Click on the Speak button to hear the speech or Click on Download button which will give you an Mp3 Audio file of the speech that will speak out the text you had given as input in step 2
Our Test Scenario
- Opening Demo app
- Selecting Voice – By default we are going to use American English (en-US): Allison (female, expressive, transformable)
- Inputting text – so our Input text would be Thank You
- Click on Download button
- Convert the Mp3 Audio file to .Wav file using pydub
- Detect the text from the .Wav file
- Compare the input text given in step 3 matches with the detected text from step 6
Automating Our Test Scenario
Create a file named test_voice_demo_app.py with the following content:
""" This is a Automation test for Text to Speech Demo app """ import os import unittest import time from selenium import webdriver class VoiceWebAppTest(unittest.TestCase): "Class to run tests against voice web app" def setUp(self): "Setup for the test" chrome_options = webdriver.ChromeOptions() prefs = {'download.default_directory' : 'path to your preferred download directory'} chrome_options.add_experimental_option('prefs', prefs) self.driver = webdriver.Chrome(chrome_options=chrome_options) self.driver.maximize_window() def test_voice_web_app(self): "Test the voice web app text to speech" url = 'https://text-to-speech-demo.ng.bluemix.net/' print 'Opening %s'%url #Open the Voice Demo App self.driver.get(url) time.sleep(5) #Scroll down self.driver.execute_script("window.scrollBy(0, -150);") time.sleep(5) #Input the text self.driver.find_element_by_xpath("//select[@name='voice']").click() time.sleep(2) self.driver.find_element_by_xpath("//select[@name='voice']/option[@value='en-US_AllisonVoice']").click() #Set input text keyword_input = 'Thank You' print 'Input text is : %s'%keyword_input input_text_area = self.driver.find_element_by_xpath("//div[@data-id='Text']/textarea[@class='base--textarea textarea']") input_text_area.clear() input_text_area.send_keys(keyword_input) #Download speech Audio Mp3 file self.driver.find_element_by_xpath("//button[text()='Download']").click() def tearDown(self): "Tear down the test" self.driver.quit() #---START OF SCRIPT if __name__ == '__main__': suite = unittest.TestLoader().loadTestsFromTestCase(VoiceWebAppTest) unittest.TextTestRunner(verbosity=2).run(suite) |
By this point , we have automated our test to download transcript.mp3 to our desired location.
Converting Audio file format
Now that, we have the Audio file of the input text with us which is in mp3 format ,but to detect the text from mp3 format is not possible , so we need to convert it to a .wav extension which is a preferred solution I found after some googling around.
To convert a .mp3 file to .wav file we will be making use of pydub opensource python package that can convert .mp3 file to various other audio file extensions.
To install this package you need to run pip install pydub
pydub internally uses FFmpeg, which is the leading multimedia framework, able to decode, encode, transcode, mux, demux, stream, filter and play pretty much anything that humans and machines have created.You can download the package from – FFmpeg builds page depending upon your system and add it to the PATH
from pydub import AudioSegment sound = AudioSegment.from_mp3("transcript.mp3") #Downloaded transcript.mp3 file which we need to convert sound.export("eng.wav", format="wav") #Output eng.wav file to detect text from |
Recognizing text from Audio file
Next, we need to detect the text from the speech for Audio file.This can be done by making use of SpeechRecognition python library.
To install the package you need to run pip install SpeechRecognition
This library has support for various Speech recognition engines which can be found at Speech Recognition Documentaion , but for my project i arbitarily used Google Speech Recognition support
import speech_recognition as sr audio = 'eng.wav' #name of the file r = sr.Recognizer() with sr.AudioFile(audio) as source: audio = r.record(source) try: recognized_text = r.recognize_google(audio,language='en-US') print('Decoded text from Audio is {}'.format(recognized_text)) except: print('Sorry could not recognize your voice') |
Asserting input text with the recognized text
assert keyword_input.lower() == recognized_text.lower(),"Detected speech text doesnt match with input text" |
Combining all the above pieces , our final test_voice_demo_app.py script would look like:
import os import unittest import time from selenium import webdriver from pydub import AudioSegment import speech_recognition as sr class VoiceWebAppTest(unittest.TestCase): "Class to run tests against voice web app" def setUp(self): "Setup for the test" chrome_options = webdriver.ChromeOptions() prefs = {'download.default_directory' : 'E:/workspace-qxf2/hackathon/Voicewebapptest'} chrome_options.add_experimental_option('prefs', prefs) self.driver = webdriver.Chrome(chrome_options=chrome_options) self.driver.maximize_window() def test_voice_web_app(self): "Test the voice web app text to speech" url = 'https://text-to-speech-demo.ng.bluemix.net/' print 'Opening %s'%url #Open the Voice Demo App self.driver.get(url) time.sleep(5) #Scroll down self.driver.execute_script("window.scrollBy(0, -150);") time.sleep(5) #Input the text self.driver.find_element_by_xpath("//select[@name='voice']").click() time.sleep(2) self.driver.find_element_by_xpath("//select[@name='voice']/option[@value='en-US_AllisonVoice']").click() #Set input text keyword_input = 'Thank You' print 'Input text is : %s'%keyword_input input_text_area = self.driver.find_element_by_xpath("//div[@data-id='Text']/textarea[@class='base--textarea textarea']") input_text_area.clear() input_text_area.send_keys(keyword_input) #Download speech Audio Mp3 file self.driver.find_element_by_xpath("//button[text()='Download']").click() time.sleep(5) #Convert Mp3 file to .Wav file sound = AudioSegment.from_mp3("transcript.mp3") sound.export("eng.wav", format="wav") #Recognize the text from Mp3 Audio file audio = 'eng.wav' #name of the file r = sr.Recognizer() with sr.AudioFile(audio) as source: audio = r.record(source) try: recognized_text = r.recognize_google(audio,language='en-US') print('Decoded text from Audio is {}'.format(recognized_text)) except: print('Sorry could not recognize your voice') assert keyword_input.lower() == recognized_text.lower(),"Detected speech text doesnt match with input text" def tearDown(self): "Tear down the test" self.driver.quit() os.remove('transcript.mp3') os.remove('eng.wav') #---START OF SCRIPT if __name__ == '__main__': suite = unittest.TestLoader().loadTestsFromTestCase(VoiceWebAppTest) unittest.TextTestRunner(verbosity=2).run(suite) |
How to run
To run the script , use command –
python test_voice_demo_app.py |
Output
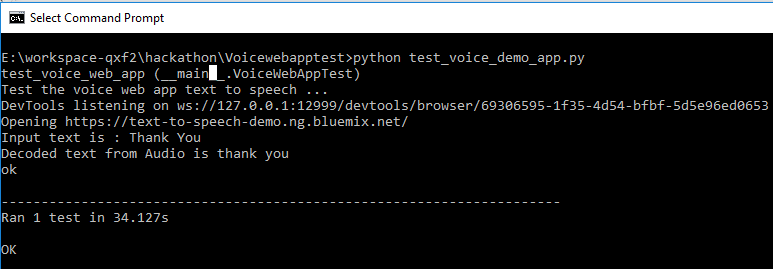
What next?
You can extend this test script to include support for various other input voice language texts available in Text to Speech Demo app by making use of various python language translator packages.
I am a software tester with more than 3 years of experience. I started my career in an e-commerce startup called Browntape Technologies. I was looking forward to work with a software testing organization which would help me showcase my testing and technical skills. So I joined Qxf2. I love scripting in Python and using Selenium. I live in Goa and enjoy its beaches. My hobbies include playing cricket, driving and exploring new places.


Hi,
Can you help me little more on it
Hi, Could you please provide more details
can we automate websocket api?
Hi Swapnil,
Following references may be helpful to you:
https://www.twilio.com/docs/voice/tutorials/consume-real-time-media-stream-using-websockets-python-and-flask
https://techtutorialsx.com/2018/02/11/python-websocket-client/
https://developer.nexmo.com/use-cases/voice-call-websocket-python
Hi Can we Automate “speech to text and text to speech” using the above?If yes can you elaborate a little ?
Hi Sreenath,
Would you please provide more details about your query?
Regards,
Rahul