At Qxf2, we did some black box testing on OpenAI Whisper – a tool that does speech recognition well. OpenAI Whisper is also capable of language detection and translation. This model can be tested in various ways, by adjusting different voice attributes such as volume, pace, pitch, rate, etc. However, in this particular case, we have chosen to test it with different accents. We did not attempt to quantify the performance but instead chose to give our “human” opinion on the output.
We tested OpenAI Whisper with 18 different English accents from around the world. Our experiment was conducted with the ‘small’ model as that is what Whisper recommends to use for English. We observed that it performs well for most accents, but it requires further training for a few specific accents. Please refer to the attached image for our observations.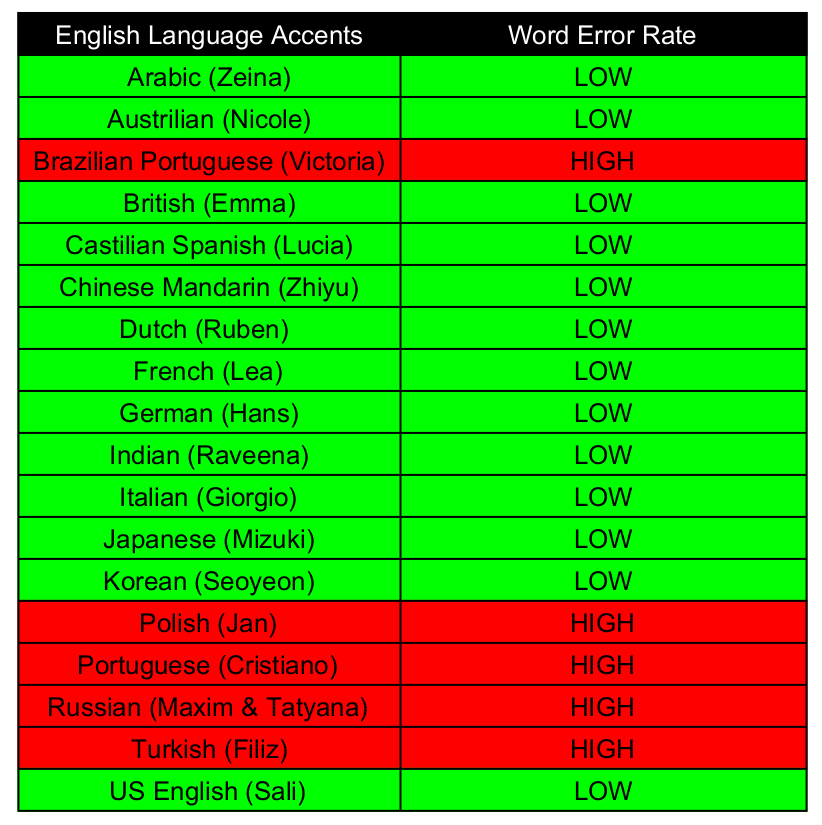
All test audio and transcriptions generated using OpenAI Whisper available here. You can download the audio files or generate your own by following the steps below to test OpenAI Whisper.
Here are the steps I followed to test OpenAI Whisper:
1. Generate test samples for testing OpenAI Whisper
2. Setup OpenAI Whisper locally
3. Test OpenAI Whisper
1. Generate test samples for testing OpenAI Whisper:
I began searching for tools that could convert text to speech, and I discovered a free online tool called Free Text-To-Speech and Text-to-MP3 Converter. This tool effortlessly transforms English text into high-quality speech at no cost. Moreover, the voices used to pronounce the texts possess unique accents, reflecting their respective languages. Additionally, the converted texts can be downloaded as MP3 files.
I generated and downloaded audio for the following base text with 18 different accents using this tool.
Whisper, oh gentle voice of the wind, carry my words to the farthest corners of the earth. Let them be heard by those who need them most, and bring comfort to those who are lost in the darkness. Whisper, and let your message spread like wildfire, igniting hope in the hearts of all who hear it.
There is nothing special about the text chosen. We are yet to test by varying the degree of difficulty in the test. For the purposes of this experiment, we limited the input to Whisper to be the above text in audio form.
2. Setup OpenAI Whisper locally:
I followed the below steps to setup OpenAI Whisper locally:
- Install PyTorch from PyTorch
- Navigate to Install PyTorch Session
- Select PyTorch Build which you want to install: I selected the stable version
- Select your OS
- Select installation package: Pip
- Select language: Python
- Select compute platform: (If you have a dedicated graphics card, please select CUDA 11.7 or 11.8 else CPU
- Now you will get a command to run on your system. In my case, I got command following command
- Install ffmpeg:
- To install it on Ubuntu or Debian, use following command:
- To install it on MacOS using Homebrew:
- To install it on Windows using Chocolatey ()
- To install it on Windows using Scoop ()
- Install OpenAI whisper:
pip3 install torch torchvision torchaudio |
sudo apt update && sudo apt install ffmpeg |
brew install ffmpeg |
choco install ffmpeg |
scoop install ffmpeg |
You can download and install/update to the latest release of Whisper with the following command:
pip install -U openai-whisper |
If you hit any issues while installation, please refer official repo: Whisper GitHub – openai/whisper: Robust Speech Recognition readme doc. Here, they noted few known issues which may help you.
3. Test OpenAI Whisper:
Used following command to generate the transcribe for all audios:
whisper --output_format txt --language English <audio file path> |
The above command will produce the transcribe of the provided audio file and save it in a text file. If you do not specify the –output_format option, Whisper will generate five different types of transcribed output files. Additionally, the transcribe can be viewed in the terminal logs. Since this command utilizes the small model by default, it doesn’t require much time to generate the output.
Lets look at the few positive and negative results which we found:
- Look at the images below for the transcribed outputs of US English, French, and Indian accents. If you compare the generated transcriptions with the base text used to generate the voice, they are almost identical. We can say that there is a very negligible word error rate for these accents.
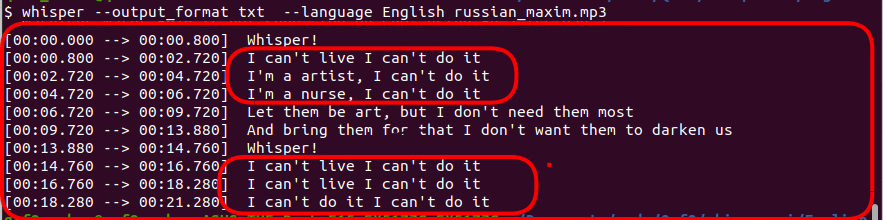
- Look at the images below for the transcribed outputs of Russian, Polish, and Turkish accents. If you compare the generated transcriptions with the base text used to generate the voice, you will notice a significant difference between them. We can conclude that OpenAI Whisper’s word error rate for these accents is high.





You can checkout all accents output here.
Observation:
Based on the above tests, we can conclude that the word error rate is high for Russian, Polish, Brazilian Portuguese, Portuguese, and Turkish accents. However, for the other 13 accents, the word error rate is minimal. It appears that Whisper has difficulty understanding Russian, Polish, Brazilian Portuguese, Portuguese, and Turkish accents.
Hire Qxf2!
Qxf2 employs technical testers. We go well beyond traditional test automation. As evidenced by this blog post, our testers can identify what aspects of quality are important to your application and perform the relevant tests. We like working with small teams and early stage products. To get in touch, fill out this simple form.

I love technology and learning new things. I explore both hardware and software. I am passionate about robotics and embedded systems which motivate me to develop my software and hardware skills. I have good knowledge of Python, Selenium, Arduino, C and hardware design. I have developed several robots and participated in robotics competitions. I am constantly exploring new test ideas and test tools for software and hardware. At Qxf2, I am working on developing hardware tools for automated tests ala Tapster. Incidentally, I created Qxf2’s first robot. Besides testing, I like playing cricket, badminton and developing embedded gadget for fun.


{kind=link}