In the world of machine learning, data takes centre stage. It’s often said that data is the key to success. In this blog post, we emphasise the significance of data, especially when building a comment classification model. We will delve into how data quality, quantity, and biases significantly influence machine learning model performance. Additionally, we’ll explore techniques like undersampling as a strategy for addressing class imbalance.
Why This Post
As a tester, gaining insights into the world of machine learning model building is invaluable. Understanding the intricacies of how ML models are constructed can provide testers with a unique advantage. It enables you to craft more effective tests, come up with better test dataset, anticipate model behaviour, and identify potential pitfalls. At Qxf2 Services we always underscore the importance of understanding the application to test well. By diving into the inner workings of model development, you’ll be better equipped to design comprehensive tests and enhance the model’s practicality.
Problem: Building a comment classification model for WordPress comments.
We set out to address a particular challenge: using machine learning on our WordPress comment dataset to build a predictive model capable of distinguishing between spam and non-spam comments. While our WordPress plugin, Titan Anti Spam is effective in filtering out most spam comments, some still manage to slip through the cracks. We didn’t create this model to replace it, Instead, our goal was to learn about building models and gain insights into the significance of data. We developed a straightforward classification model for comment categorisation, opting for the Bayes classifier.
Please note that this blog primarily delves into our data manipulation journey rather than extensive model-building details.
Solution: Building and Refining the Model.
Preparing and Refining the Model Data
Our objective was to develop a model that could effectively distinguish between spam and non-spam comments. To achieve this, we utilized a dataset of comments from our WordPress website. The dataset contained various fields, but our focus was primarily on extracting the comments and their corresponding labels (0 or 1). These labels were obtained through a combination of manual human labelling of comments as spam or non spam and the utilization of a WordPress plugin, accumulated gradually over time. Additionally, some preprocessing steps were necessary to remove special characters and quotation marks. We also ensured that the labels were simplified to have ‘0’ for spam messages and ‘1’ for non-spam messages. This data was saved to a text file so that we could use it for building our classification model. You can find the refined data set here
Initial Model and Challenges
The main steps involved here were:
def load_data(input_data): """Load data from a text file and return a DataFrame.""" txt_data = [] with open(input_data, "r", encoding="utf-8") as txt_file: reader = csv.reader(txt_file, delimiter=',') # Skip the header row next(reader) for row in reader: if len(row) >= 2: comment_text = row[0] label = row[1] txt_data.append((comment_text, label)) return pd.DataFrame(txt_data, columns=['sentence', 'label']) |
def preprocess_data(input_data): """Preprocess the data, including text cleaning and stemming.""" # Initialize the SnowballStemmer stemmer = SnowballStemmer("english") # Define custom preprocessing function using SnowballStemmer input_data['sentence'] = data['sentence'].apply(lambda x: " ".join([ stemmer.stem(i) for i in x.split()])) return input_data |
def train_model(x_train, y_train): """Train a text classification model.""" # Define the pipeline with feature extraction and classification steps pipeline = Pipeline([ ('vect', TfidfVectorizer(ngram_range=(1, 4), sublinear_tf=True)), ('chi', SelectKBest(chi2, k=1000)), ('clf', MultinomialNB()) # Using Naive Bayes classifier ]) # Fit the model model = pipeline.fit(x_train, y_train) return model |
def evaluate_model(model, x_test, y_test): """Evaluate the model on the test data.""" # Predict the labels for the test set y_pred = model.predict(x_test) # Calculate performance metrics acc_score = accuracy_score(y_test, y_pred) conf_matrix = confusion_matrix(y_test, y_pred) recall = recall_score(y_test, y_pred, pos_label='1') precision = precision_score(y_test, y_pred, pos_label='1') f1score = f1_score(y_test, y_pred, pos_label='1') return acc_score, conf_matrix, recall, precision, f1score |
You can find the complete code here
After running the tests against this model, the results looked as shown below
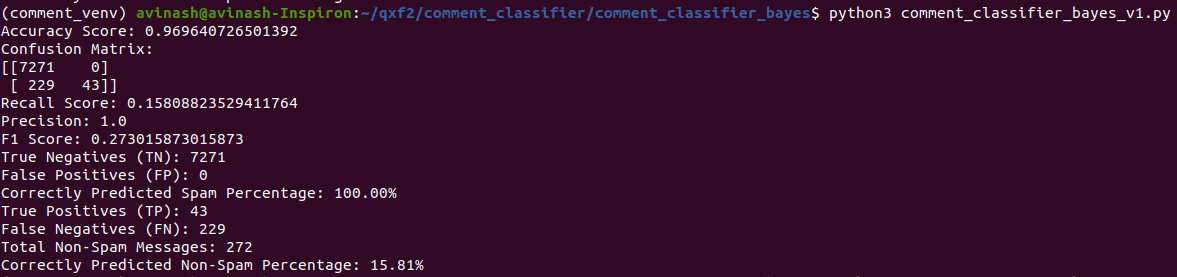
The model had high accuracy at around 96.9% and did a good job in identifying spam messages. However it struggled with non-spam messages, getting them right only 15.81% of the time. This difference in performance suggests that the model might be leaning too much towards classifying messages as spam. This bias could be due to the training data, which had approximately 36,285 spam messages and about 1,429 non-spam messages.
Undersampling Strategies
As we realised that our data had a lot more spam messages than non-spam ones, we explored ways to fix this imbalance. We found a technique called RandomUnderSampler, which helps us under-sample the majority class by randomly picking samples. This allows us to balance the majority class. By setting the sampling_strategy to 1.0, we ensure an equal percentage of spam and non-spam messages.
def undersample_data(x_data, y_data, target_percentage=1.0): """Undersample the majority class to achieve the target percentage.""" sampler = RandomUnderSampler(sampling_strategy=target_percentage, random_state=42) # Convert the Pandas Series to a NumPy array and reshape them x_data = x_data.to_numpy().reshape(-1, 1) y_data = y_data.to_numpy().ravel() # Use ravel to convert to 1D array # Undersample the data x_resampled, y_resampled = sampler.fit_resample(x_data, y_data) # Convert the NumPy arrays back to Pandas Series x_resampled_series = pd.Series(x_resampled[:, 0]) y_resampled_series = pd.Series(y_resampled) return x_resampled_series, y_resampled_series |
Below is the results with target_percentage=1.0
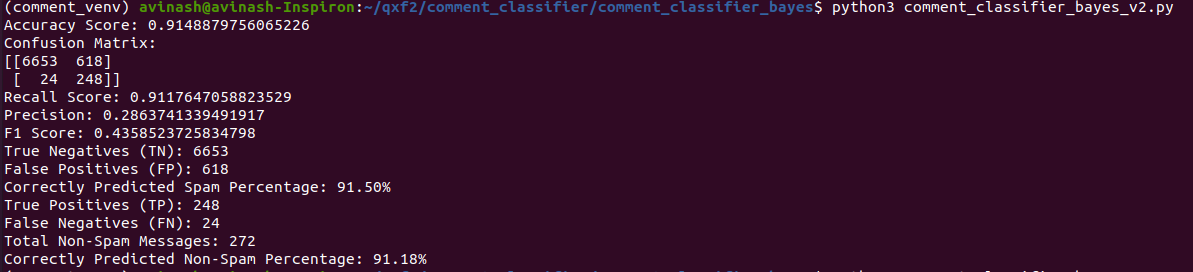
Result with random undersampling 1.0
When we applied Random Undersampling with a ratio of 1.0, the model improved its ability to identify non-spam messages, although the overall accuracy decreased. Therefore, we experimented with various sampling strategies. Using a Random undersampling ratio of 0.3, we observed significant improvements in accuracy and the F1 score.
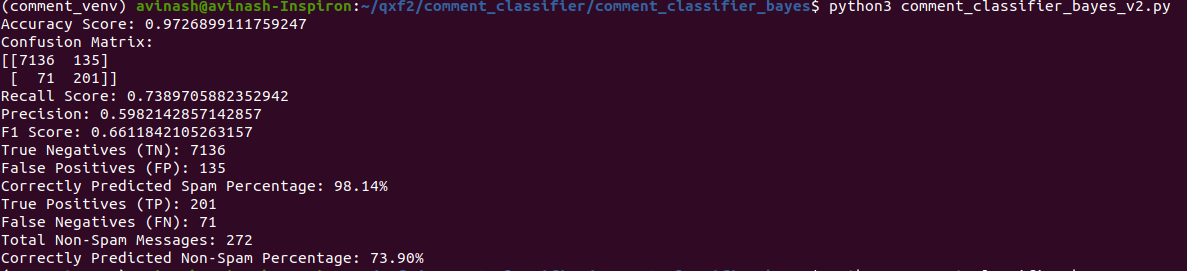
We can now put our model into action to effectively classify WordPress comments. For future use, we’ve also stored the model to a pickle file.
Conclusion and Takeaways
In short, we’ve discussed how we built a model to classify WordPress comments. We covered the steps from identifying the problem to finding a solution. Our solution involved preparing data, creating an initial model, and dealing with data imbalance problem using undersampling technique.
But, our journey isn’t over yet! In our next blog post, we’ll explore how to test these models and make them even better. So, stay tuned for more tips on improving your machine learning models. As QA professionals, understanding the insights behind these models is crucial for us. It helps us test the models effectively and ensure their quality. Stay tuned for more insights into the world of machine learning and quality assurance!
Hire QA from Qxf2 Services
Qxf2 is a group of skilled technical testers proficient in both conventional testing approaches and addressing the distinct challenges of testing contemporary software systems. Our expertise lies in testing micro services, data pipelines, and AI/ML-driven applications. Qxf2 engineers are adept at working independently and thrive in small engineering teams. Feel free to contact us here.

I am a dedicated quality assurance professional with a true passion for ensuring product quality and driving efficient testing processes. Throughout my career, I have gained extensive expertise in various testing domains, showcasing my versatility in testing diverse applications such as CRM, Web, Mobile, Database, and Machine Learning-based applications. What sets me apart is my ability to develop robust test scripts, ensure comprehensive test coverage, and efficiently report defects. With experience in managing teams and leading testing-related activities, I foster collaboration and drive efficiency within projects. Proficient in tools like Selenium, Appium, Mechanize, Requests, Postman, Runscope, Gatling, Locust, Jenkins, CircleCI, Docker, and Grafana, I stay up-to-date with the latest advancements in the field to deliver exceptional software products. Outside of work, I find joy and inspiration in sports, maintaining a balanced lifestyle.


An insightful exploration emphasizing the critical role of data quality in constructing and enhancing Classification Models for accurate predictions