In the world of machine learning, assessing a model’s performance under real-world conditions is important to ensure its reliability and robustness. Real-world data is usually not perfect, it may contain messy data or data with noise, outliers, and variations. During model training, these types of data could be limited, and the model may not have received sufficient training to handle them effectively. This lack of training could lead to problems when encountering such data. Standard tests on typical datasets may not adequately capture the challenges posed by such imperfect data, potentially overlooking critical issues that can hinder model effectiveness. To address this, robustness testing emerges as a powerful approach to evaluate machine learning models under more demanding scenarios.
By designing and utilising datasets specifically tailored to mimic real-world challenges, we gain valuable insights into a model’s resilience and its ability to handle adverse conditions. In this post, we will delve into the significance of robustness testing and explore the key considerations when crafting robust datasets, particularly focusing on noisy data or perturbations in the data. By doing so, we equip ourselves with the means to uncover hidden bugs and make our models more resilient and adaptive to challenging real-world scenarios.
Why This Post
As part of R&D at Qxf2 services, we aim to expand our understanding of testing Machine Learning models. Our main focus is to thoroughly explore the fundamental aspects of testing models with various datasets and how to effectively apply these principles in real-world scenarios. By researching more into this topic, we hope to develop our knowledge and skills in testing machine learning models effectively, ensuring their reliability and performance in practical scenarios. This post will provide valuable insights on designing noisy test data to thoroughly test a Machine Learning model. By the end of this blog section, you will be equipped with the knowledge and techniques to create robust datasets that can help effectively test your ML models in the real-world scenarios.
Problem: Testing a Classifier Model
We had previously developed an app for testers to practice testing AI/ML based applications. The app is hosted on Github. It helps to classify a message as a leave message or not a leave message (PTO or Non-PTO message).
To test this application you would create test data representing both categories and ensure the results provided are accurate. For this you would either get or create some labelled data set messages and calculate some score based on accuracy, precision, recall and f1 score etc. However, just evaluating your model on this score may not prove your model works good. Considering some other criteria is also important as real-world data would often deviate significantly. We must account for various factors such as messages with special characters, typos, random words inserted, or sentences framed inappropriately. Incorporating these critical elements into our testing process becomes important to assess the app’s resilience and robustness in handling diverse and challenging inputs.
Neglecting robustness testing in the evaluation of a model can have significant consequences. When robustness is not considered, the model’s performance might not be accurately represented under real-world conditions, leading to unreliable predictions. Data perturbations can have a negative impact on the performance of a machine learning model. An adversarial attack involves generating such perturbations that can significantly decrease the model’s effectiveness. Ignoring robustness testing can also hinder the model’s generalisation and introduce biases that may remain undetected. To ensure a comprehensive evaluation and build a trustworthy classifier, it is crucial to incorporate robustness testing throughout the model development and deployment process.
Solution: Creating a Noisy Dataset for Robustness Testing
The concept of a noisy dataset involves introducing variations, errors, or perturbations into the input data, simulating real-world conditions where data is rarely clean and subject to unpredictable variations. Evaluating model robustness using noisy datasets helps assess the model’s performance under challenging and diverse inputs.
Knowledge of model features can be useful to design the noisy dataset effectively. Some of the noise which we introduced to test our model were:
- Random Word Insertion: Add irrelevant words or phrases to the input message.
- Random Word Deletion: Remove random words or phrases from the input message, making it less coherent.
- Character Substitution: Randomly replace characters in the message, potentially creating typos or misspellings.
- Word Shuffling: Rearrange the words in the message randomly while preserving sentence structure.
- Synonym Replacement: Replace certain words with their synonyms, maintaining the overall meaning.
- Punctuation Variation: Add or remove punctuation marks, potentially altering sentence semantics.
- Random Capitalisation: Randomly capitalise or lowercase words, disrupting the text flow.
- Emoji Insertion: Add random emojis to the message without affecting its classification.
- Repetition: Repeat certain words or phrases to test the model’s ability to identify duplicates.
- Changing Tense: Convert verbs to different tenses (e.g., present to past or future tense).
- Numerical Variation: Alter numerical values in the message, changing numbers or using random digits.
- Mixed Languages: Introduce text in other languages within the message to test language robustness.
- HTML Tags or Special Characters: Inject HTML tags or special characters, simulating real-world data sources like web forms or chat logs.
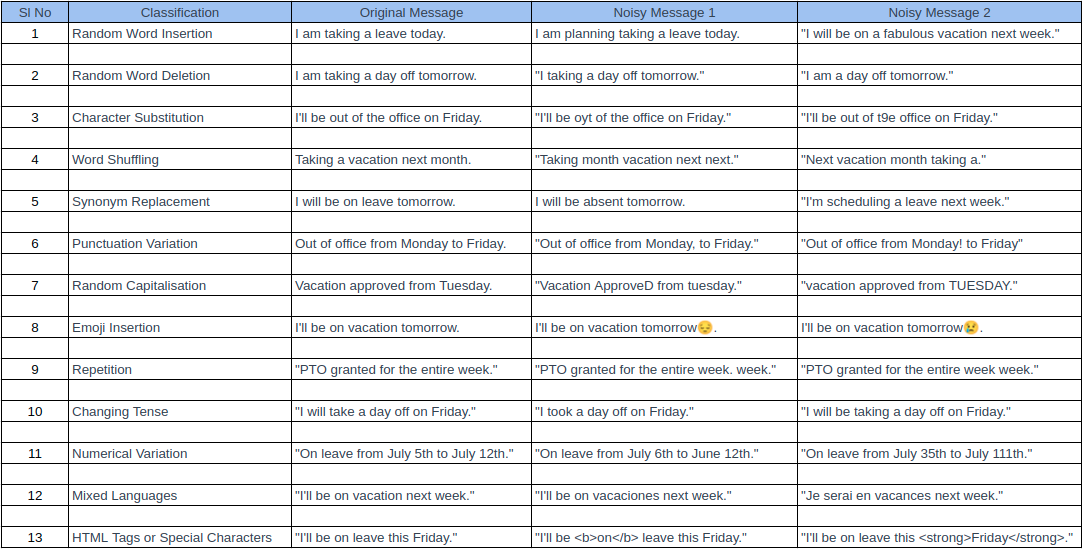
These are the few noisy dataset scenarios which can be included in most of the NLP classification models. By incorporating these, we can design a diverse and representative noisy dataset that will help us thoroughly assess the robustness of our PTO detector app.
Test script to test the app
To perform the test, I’m using the Python request module to send a POST request to the URL https://practice-testing-ai-ml.qxf2.com/is-pto. While we have the option to directly use the model for message classification, certain data cleaning operations are required before making predictions. To maintain simplicity, I’ve chosen to utilise the API endpoint, even though it adds a slight delay to the process. The test results, along with the messages, are saved to a CSV file. The complete code for the test file can be found below.
""" Test Script to test a PTO classifier app for Noisy dataset """ import csv import requests class TestPTOClassifier: """ A class to test PTO classifier """ def make_predictions(self, messages, url): """ Predicts whether a given message is PTO or non-PTO by making the api call to the endpoint. """ predictions = [] for message in messages: data = {'message': message} response = requests.post(url,data=data) predictions.append(response.json()['score']) return predictions def open_input_file(self, input_csv): """ Open the input CSV file and return the reader object. """ with open(input_csv, newline='', encoding='utf-8') as csvfile: reader = csv.DictReader(csvfile) data = list(reader) return data def save_to_output_file(self, output_csv, fieldnames, predictions): """ Save the predictions to the output CSV file. """ with open(output_csv, 'w', newline='', encoding='utf-8') as outfile: writer = csv.DictWriter(outfile, fieldnames=fieldnames) writer.writeheader() # Write the predicted results for each row writer.writerows(predictions) def classify_csv(self, input_csv, output_csv, url): """ Classifies messages from an input CSV file and saves the results to an output CSV file. """ predictions = [] # Open the input CSV file reader = self.open_input_file(input_csv) for row in reader: original_message = row['Original Message'] noisy_message_1 = row['Noisy Message 1'] noisy_message_2 = row['Noisy Message 2'] # Make predictions for all messages predictions_per_message = self.make_predictions( [original_message, noisy_message_1, noisy_message_2], url ) # Unpack the predictions for each message prediction_original, prediction_noisy_1, prediction_noisy_2 = predictions_per_message # Append the predicted results to the list predictions.append({ 'Original Message': original_message, 'Original Prediction': prediction_original, 'Noisy Message 1': noisy_message_1, 'Noisy Message 1 Prediction': prediction_noisy_1, 'Noisy Message 2': noisy_message_2, 'Noisy Message 2 Prediction': prediction_noisy_2 }) # Define the fieldnames for the output CSV file fieldnames = ['Original Message', 'Original Prediction', 'Noisy Message 1', 'Noisy Message 1 Prediction', 'Noisy Message 2', 'Noisy Message 2 Prediction'] # Save the predictions to the output CSV file self.save_to_output_file(output_csv, fieldnames, predictions) print("Predictions saved to", output_csv) if __name__ == '__main__': # Creating a classifier object classifier = TestPTOClassifier() PTO_URL = "https://practice-testing-ai-ml.qxf2.com/is-pto" # Path to your input CSV file INPUT_CSV = 'noisy_data.csv' # Path to save the results OUTPUT_CSV = 'noisy_data_result.csv' # Classify the messages from the input CSV and save predictions to the output CSV classifier.classify_csv(INPUT_CSV, OUTPUT_CSV, PTO_URL) |
Test result:
As you can observe, introducing some noise in a few cases such as Random Word Insertion and Synonym Replacement has caused the model to fail predict the correct classification. Moving forward, we can focus on refining these datasets and further investigate the model’s behaviour to identify similar issues, enabling us to enhance the performance of our models.

Conclusion
To sum up, incorporating noise or perturbations in the data for evaluating model robustness is crucial for developing dependable and resilient machine learning models. Collaborating with your team to enhance the design of these datasets can yield better insights. By doing so, you obtain a more realistic reflection of real-world scenarios, detect model vulnerabilities, and ultimately enhance generalisation and performance in real-world applications.
Moving forward, we will continue to focus on such data testing of model and share our findings. Additionally, we will explore the creation of datasets for word replacement, which proves to be a valuable aspect in testing ML models. Until then, happy testing and learning!
Hire QA from Qxf2 Services
Qxf2 is a team of technical testers who excel in both traditional testing methodologies and tackling the unique complexities of testing modern software systems. We specialise in testing microservices, data pipelines, and AI/ML-based applications. Qxf2 engineers work well with little/no direction and prefer working with small engineering teams. You can get in touch with us here.

I am a dedicated quality assurance professional with a true passion for ensuring product quality and driving efficient testing processes. Throughout my career, I have gained extensive expertise in various testing domains, showcasing my versatility in testing diverse applications such as CRM, Web, Mobile, Database, and Machine Learning-based applications. What sets me apart is my ability to develop robust test scripts, ensure comprehensive test coverage, and efficiently report defects. With experience in managing teams and leading testing-related activities, I foster collaboration and drive efficiency within projects. Proficient in tools like Selenium, Appium, Mechanize, Requests, Postman, Runscope, Gatling, Locust, Jenkins, CircleCI, Docker, and Grafana, I stay up-to-date with the latest advancements in the field to deliver exceptional software products. Outside of work, I find joy and inspiration in sports, maintaining a balanced lifestyle.

