We have an application which holds some sensitive survey information. Now since we couldn’t share the data with everyone we wanted a good way to Anonymize the data so that we can handover the development to anyone. We found Faker as a good library that generates fake data.
Why this post
As a tester, we may need to work with real data but in case the data has some sensitive information, it may be not possible to use it directly. In such cases anonymizing the data becomes important. In this post, you will learn how to Anonymize the data using Faker
What is Faker?
Faker is a Python library that generates fake data for you. You can use it to Anonymize your production data, create dummy data for testing by filling it in your DB, etc
Installation
To install faker you can simply run
pip install Faker |
Next, as part of our example, we will be dealing with CSV data so to iterate over the csv data we need to install a python library called Unicode CSV by running
pip install unicodecsv |
Working example to anonymize data from a csv file
Contents of original_data.csv file
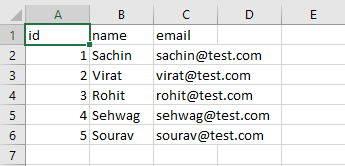
Consider we have a CSV file named original_data which has 3 columns namely Id, Name and Email with 5 records for the same as shown in the screenshot above of which we will be anonymizing the cell values for Name and Email columns by making use of Faker library
Create a file named anonymize_data.py with the following content:
""" This script will Anonymize the data in original_data.csv file to Anonymized form in anonymized_data csv file """ import unicodecsv as csv from faker import Faker from collections import defaultdict def anonymize(): 'Anonymizes the given original data to anonymized form' # Load the faker and its providers faker = Faker() # Create mappings of names & emails to faked names & emails. names = defaultdict(faker.name) emails = defaultdict(faker.email) with open("original_data.csv", 'rU') as f: with open("anonymized_data.csv", 'wb') as o : # Use the DictReader to easily extract fields reader = csv.DictReader(f) writer = csv.DictWriter(o, reader.fieldnames) writer.writeheader() for row in reader: row['name'] = names[row['name']] row['email'] = emails[row['email']] writer.writerow(row) if __name__ == '__main__': anonymize() |
As you can see in the code you can simply fake a name by using the method – faker.name. Each call to method faker.name() yields a different (random) result similarly for emails. Faker object has around 158 different methods all of which generates fake data depending on users need. Faker delegates the data generation to providers. The default object provider uses the English locale. Faker supports other locales; they differ in the level of completion. If you wish to use some other locale provider then you can visit – Faker Locales
You can run the script with
python anonymize_data.py |
which would generate an anonymized_data.csv in the same directory of your python script with your anonymized data
Contents of newly generated anonymized_data.csv
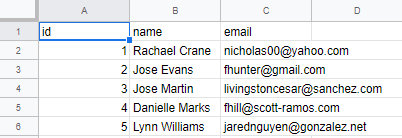
You can see that anonymized_data.csv file has a similar number of rows, length and also field name only difference is that names and emails have been replaced with anonymized names and emails
Hope this post helped you to learn how with some lines of code you can easily fake a dataset. So next time when your team says they can’t use real time data since it has sensitive info, share your knowledge on this library and get the data rolling. Happy testing…
I am a software tester with more than 3 years of experience. I started my career in an e-commerce startup called Browntape Technologies. I was looking forward to work with a software testing organization which would help me showcase my testing and technical skills. So I joined Qxf2. I love scripting in Python and using Selenium. I live in Goa and enjoy its beaches. My hobbies include playing cricket, driving and exploring new places.


What is file is having duplicate data still faker will give you same data for both the rows
eg: input file has
id first_name cash
101 ravi 10
102 chandra 200
101 ravi 20
here id is values repeated for two rows in this case will faker give same data for id ?
Hi,
After referring faker documentation it looks like the duplication removal mentioned in your case won’t happen directly in the faker as faker generator, generates data by accessing properties named after the type of data. More details at below documentation.
https://pypi.org/project/Faker/
However, you can sanitize original CSV file removing duplicates. The code sample is shown in the below article:
https://stackoverflow.com/questions/7682796/python-removing-duplicate-csv-entries
Then use the code snippet shown in the blog post.
Also, you can use random.randint() to generate random id’s as shown in the below reference document:
https://www.geeksforgeeks.org/python-faker-library/
Another reference you may want to refer as well:
https://medium.com/district-data-labs/a-practical-guide-to-anonymizing-datasets-with-python-faker-ecf15114c9be
Regards,
Rahul
Can we do anonymization of data for multiple files, maintaining the data uniformly using faker?
For example,
InputFile A has Customer_Name: John Smith
InputFile B has Employee_Name: John Smith
While Anonymizing the data, can we achieve
OutputFile A Customer_Name: Jane Doe
OutputFile B Employee_Name: Jane Doe
Yes..We can achieve it ..You can define function anonymize() for two different files, one is FIle A and the other is File B.
Thanks,
Nilaya
Hey, first of all thanks for the post. I’m getting an error in the line
writer = csv.DictWriter(anonymized_file, reader.fieldnames)
AttributeError: ‘str’ object has no attribute ‘decode’. Did you mean: ‘encode’?
What version of Python is this post using? thanks
Hi,
This blog post uses Python version 2.7.17. This has support only till 3.5. For example, when we tried to run in Python 3.7, we observed the following message:
Supported versions are python 2.7, 3.3, 3.4, 3.5, and pypy 2.4.0.