Testing loosely coupled microservices, at least for me, has proven to be much more challenging than testing monoliths. I feel like a beginner again – especially when there are many teams and many independently deployable services. I often feel overwhelmed with how much there is to consider!
In this post, I present a mental model that is helping me think better about testing applications that are loosely coupled microservices. This post might help you if you are leading the testing efforts of such applications and/or if your testing background is predominantly in the world of monoliths. I have interspersed this post with contextual tips to help you implement these ideas at your company. The pattern in this post is to start with something familiar (i.e., testing monoliths) and then extend it to testing in the world of microservices. I hope starting with the familiar might make the unfamiliar less scary.
NOTE 1: Though this post looks theoretical, you should play along! Work on the tasks listed in the sections labeled YOUR TASK
NOTE 2: This post is NOT meant for folks with deep experience testing microservices. For you folks, many things I talk about here will come off as quaint and primitive.
Why this post?
This post is long overdue. In the last couple of years, my colleagues at Qxf2 and I have been wrestling with the challenge of testing loosely coupled microservices at early stage startups. We were late to the party and had to play catch up. While we are definitely NOT experts, I feel like our mental models right now are ripe enough to share and get feedback. Having shared this work with small groups over the last 6-months, I am optimistic that this write up will help testers with tons of experience in monolith-land (like me!) to transition into testing better in microservices-land.
The basic mental model
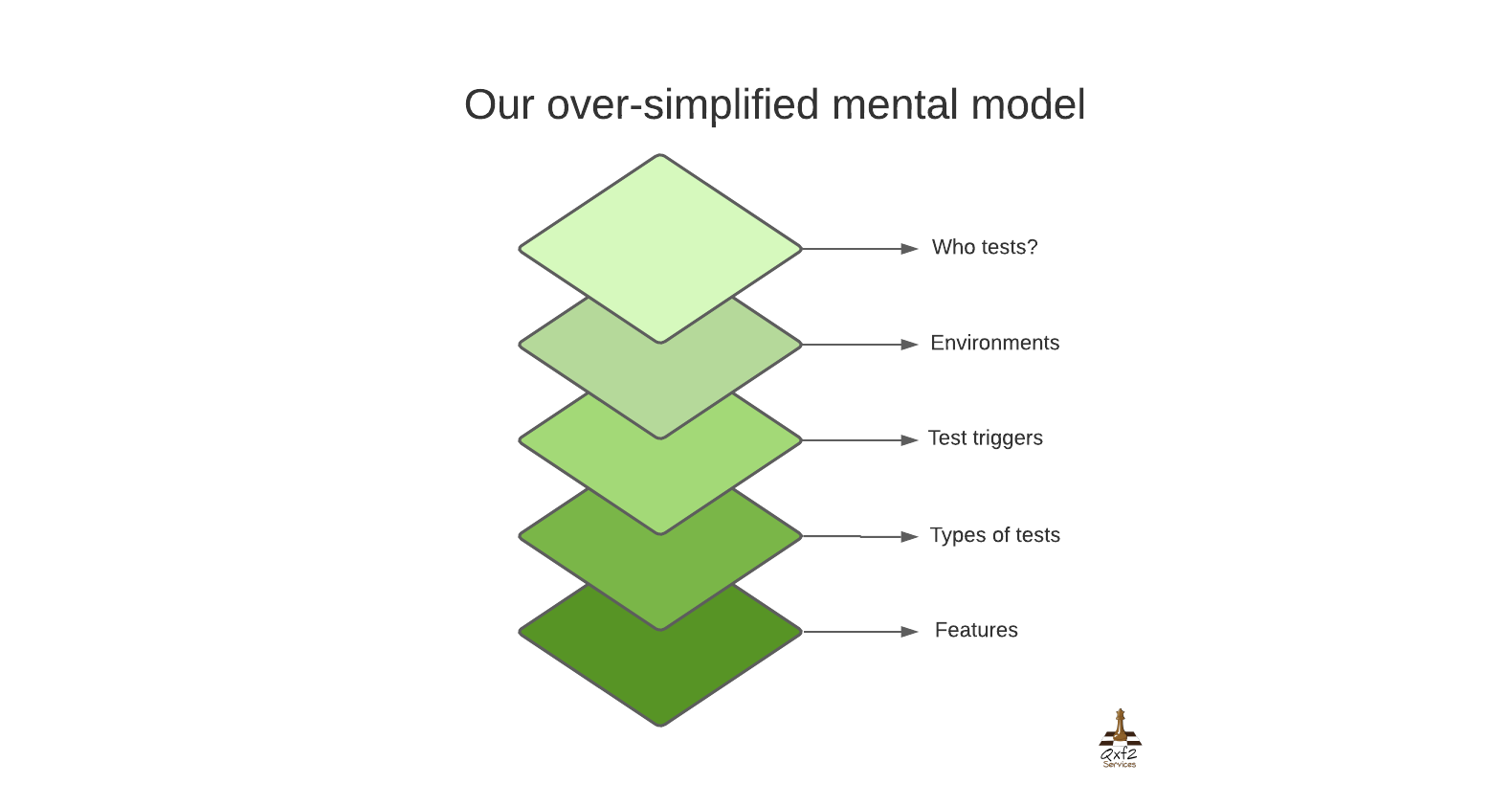
We are going to be working with the mental model in the image below. We will work our way through five crucial considerations that we take into account when testing monoliths: who tests, environments, test triggers, types of tests and features to test. I know that there are several more factors that are different between testing monoliths and testing loosely coupled microservices like how information flows between teams, release schedules, etc. However, I wanted to make this post useful to a large cross-section of testers. So in the context of this post, I feel like limiting our discussion to these five factors will be sufficient to give us a really solid transition point.
TIP 1:
If you ever present this to your team, please make sure to set two expectations clearly. One, you will do a lot of the heavy lifting. You will break up the high level thinking into concrete, actionable problems that the team can solve. Others do not need fit all the thinking we are going to do into their head! Two, you do NOT want an army of testers. Many executives see this work and assume I am angling for an army of testers! Far from it, I think the footprint of testers has to be small. Involving every other role in testing is the way to go.
But isn’t this overkill?
Overkill! That is the initial impression of everyone I have shared this work with. This reaction is OK for most non-professional testers. But as a professional tester, I feel like we must make an attempt to generalize our testing. If you are a professional tester, I promise you that working through this post has several benefits:
a) This analysis plays very well with executives
b) Your team (and you) get more confidence that testing has been thought about systematically
c) The visualizations here will help you track testing progress over time
d) Improved presence of mind and situational awareness in technical conversations
e) Creating a checklist of ideas that you might want to implement someday
f) Help in selecting a more appropriate QA tool belt for your team
g) Initiating conversations early so that complex tasks get more soak time
h) Identifying easy wins that your team might have missed
i) Better planning within sprints to account for testing
TIP 2:
Fight the test pyramid! Most teams get overwhelmed when presented with this information. They water down discussions to focus only on ‘types of tests’. Their instinct is to think in terms of a pyramid! Fight that idea right from the start. This post will help you expose why thinking in terms of a test pyramid is insufficient when testing loosely coupled microservices.
Let us begin for real now. I will sequence our walkthrough in the following order:
1. Who tests?
2. Environments
3. Test triggers
4. Types of tests
5. Features
I am choosing this order on purpose. Coming from monolith land, we are used to one-dimensional thinking about who tests, environments and test triggers. In non-monolith land, there are many more considerations around these three aspects. I believe as testers, we are better suited to grasp the increase in types of tests and features. So I will leave those for last.
1. Who tests?
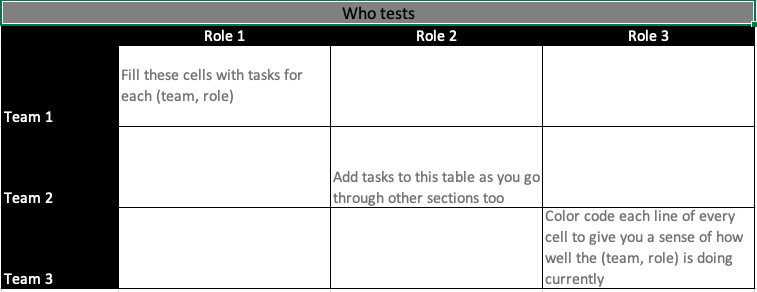
In monolith land, we could answer this question with by listing job roles like testers, developers, etc. In microservices land, the answer is a bit more complicated. We need to consider the teams involved too. Further, unless your architecture is pristine and your microservices are truly independent and small, there will be overlap of testing responsibilities between teams. So different teams might need to execute some common subset of tests.
YOUR TASK
Create the above matrix for your application. List all the teams in a column and all the roles in a row. For each cell in the table, think about what that combination of (team, role) can test. You can continue to add tasks as you work through other sections of this post. Color-code each line of each cell in your matrix – green if the (team, role) is already doing a good job and red or grey if they are currently doing a poor job or not even doing the task itself. This will eventually help you when you need to break this thinking down into a concrete set of tasks and then present the appropriate subset of tasks to the relevant (team, role) combination. This sort of task breakdown, especially the common ones for a role across all teams, will also help when new teams are being created. This exercise assumes you are working at a place with less than (say) forty small-teams.
BTW, If you work at a company that deals with death-star architectures, skip reading this post and start writing your own! You folks are well ahead of us and I would love to learn from your experience.
The goal of this task is for you to be aware of all the folks you would like to involve in testing. Now, identify at least one testing task each of them could work on. As you proceed through this post, whenever you think of new responsibilities, try and place them within this matrix. Testing in microservices land is a true team effort – remember this because too often your team members and executives might forget this fact and will need you to remind them!
TIP 3:
DRY does not apply to defense. When playing defense, we want to have multiple layers. Multiple layers mean that there will be some common checks between multiple tests.
2. Environments
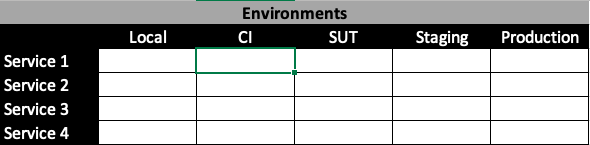
We are used to working with different environments in monolith land. The usual suspects are local, CI, System Under Test (or SUT), staging and production. Those still remain in microservices land. So thinking about environments should be easy, right? Not really! Each microservice we deal with can potentially have its own environment, its own deploy procedure and be associated with specific cloud infrastructure. These make things complicated.
For example, AWS lambdas are not easy to deploy on local and CI environments. You might need special tooling like localstack for that. Further, if infrastructure is saved as code, the deploy scripts might not have been written to support local deploys. There is a bunch of complexity involved here. Luckily for us, we will not need to run all tests for all services on all environments. We can be much smarter. Working through this section will help us consciously choose whether we want to run certain tests for a specific service on a given environment. You can safely apply your standard “tester like” thinking around frequency of change, risk potential and duration of tests to make choices once you have filled out the matrix below.
YOUR TASK
Create the above matrix for your application. List out environments you have and the different services you have. Mark the cells in grey if you cannot deploy the service onto the environment automatically. Mark them in green if you can make automated deploys for a service to a given environment. You are simply evaluating if a service can be deployed (not tested!) to a specific environment.
Doing the above exercise has several benefits. I find that most engineering executives perk up and take action when they realize many cells in this table are grey. It also helps set concrete and visible quality goals for engineering. I will add a note here from personal experience. Most teams start with very little green. In fact, most of the testing on the local environments are limited to unit tests. Further, there could be massive technical challenges if there are common/shared data sources. The point is not to be discouraged and give up but to make a conscious choice about what tests you (can) run where.
TIP 4:
Take a lot of developer and DevOps help! You do not need to do everything on your own. Doing this exercise will help you come up with a concrete set of requests. You can also ask your developers help in architecting the test automation – e.g.: how to split your tests across repos? These are real technical challenges where non-QA roles can help quite a bit!
3. Test triggers
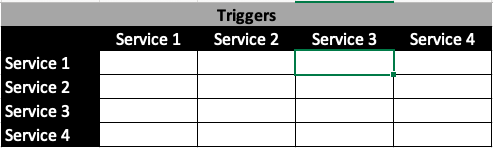
We are used to having two types of test triggers – event based and time based. Events are typically a commit to version control. Time-based triggers revolve around release dates, nightly test runs, etc. That portion remains the same in microservices land …. except that each service can have an independent commit. So it is pretty important that we think through what set of tests we need to run when a change happens to a specific service. We also need to think about how frequently a service might change and how critical it is to your application.
YOUR TASK
If feasible, create the above crosstable for your application. The first column represents the service that is changing i.e., the trigger. The row associated with that service denotes the testing effort required by each of the other services in response to the trigger. Assume a service changes. Colour code that row to denote the testing effort needed. Mark the cells in shades of yellow to denote the testing effort required. Dark yellow, if your intuition says you need to run most tests, very light yellow if your intuition says you need to run only a small subset of tests and leave the cell white if you do not need to test a service in response to the trigger. This portion is judgement based.
As an example, let us assume our application is made up of a sequential (one way) pipeline of 4 services. When a commit is made to service 3, we might want to spend most of our effort testing service 3 and some effort in testing service 4 but nearly no effort testing service 1 and service 2. This is just a dumb example. In the real world, you will need to think deeper.
This might seem like a cumbersome process but when you do this exercise, you might realize that you need run a very small subset of tests for certain services. If all your cells are in dark yellow, it points to some sort of architectural problem or a problem with your ability to prioritize testing effort.
Once you have this matrix, you can start talking to your DevOps folks. Show them this and ask them about how to setup intelligent pipelines to execute different subset of tests depending on the trigger. Chances are, they might want to begin with just 2-3 simple configurations. That is ok. It is still better than having only one single pipeline that executes everything all the time.
TIP 5:
For early stage products, initiating these kind conversations with DevOps is far more valuable than resolving these conversations. Spotting problems like these early and allowing engineering teams to design and iterate on solutions turns out to be useful for everyone involved.
4. Types of tests
Coming from a background of testing monoliths, you need to expand your thinking to include a few more types of tests and testing techniques. For reasons I cannot get into here, I do not like the analytical breakdown of tests into UI, API, integration, etc. In fact, I do not like talking about the types of testing at all. Further, you can learn a lot about types of tests on the Internet since most developer lead testing teams focus on this sort of break up. So I will keep this section super relevant to the new items.
One, you have to know how to test on production. Luckily someone super smart has written a lot about testing microservices on production. Read this series of blog posts and pick up tips. Learn to configure simple sanity tests on production. Ask for monitoring and alerting when your features are being fleshed out.
Two, get used to contract testing. This is becoming famous within the testing world these days. You can find more than enough material online to teach you how to do contract testing. I will warn that the hardest part about contract testing is getting the different teams to agree to implement contract tests.
Three, get used to service virtualization as a technique for testing. You might have already been doing this with monoliths. But with microservices, virtualizing services is somewhat unavoidable.
Four, you might need to start thinking about the quality of data if you are working with data intensive applications. As of now, we like Great Expectations in this space.
Five, graduate from developing test frameworks to developing a testing stack. You will need more one-off QA tools especially in the messy places where no team definitively owns a feature or artefact. I will add that reporting test results in the context of microservices is a mess and an underserved area. If there are entrepreneurs who would like to pick my brain about the problems, please reach out.
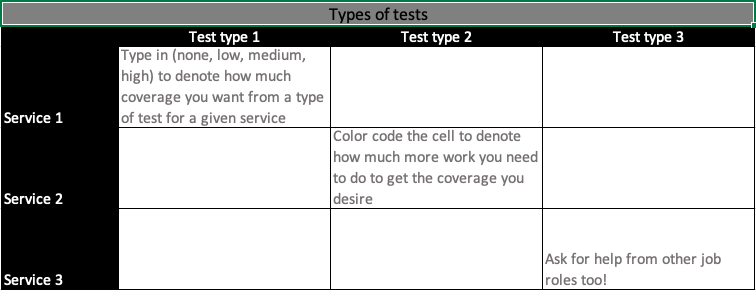
YOUR TASK(s)
Create the above matrix for yourself. In each cell, type in a word (like ‘high’) to denote the amount of coverage you would like to have for that specific service and type of test. Color code each cell to denote how much more work you need to get to the desired coverage.
Additionally, think about the extra types of tests you might want to add to your current test suite for each service. Start looking for tooling in those spaces. Know just enough to be able to propose them as a solution when the right moment arises. Initiate conversations with engineers who might know more.
TIP 6:
The “inside out” vs “outside in” or “end to end” thinking does not make too much sense in this context. Our application suddenly has so many more entry and exit points! I made a mistake with my initial mental model. I assumed that since a monolith could be thought of as a blackbox, loosely coupled microservices could be thought of as multiple black boxes. That mental model completely ignores the interconnection between the different black boxes! Once I arrived at that spot, I was able to see why commonly used terms like “end to end” and “outside in” were not useful when talking about testing loosely coupled microservices.
5. Features
We are almost at the end of this post! This section can be short since features are what we excel at testing. I have only two things to add.
One, treat your infrastructure (probably stored as code) as a feature as well. Think about how to test deploys and configurations. There is a whole world around testing Infrastructure as Code. I have zero experience in this area. However, one of my colleagues and an ex-colleague are working on the problem. Talking to them, I have learnt that there are systematic ways to test infrastructure that is saved as code. I have learnt of tools like Terratest and Testinfra. I have also seen them write health checks for services and endpoints and seen them test configuration changes. Since I am a newbie in this area, I just want to point out that we should consider infrastructure as a feature as well when we move from testing monoliths to testing loosely coupled microservices.
Two, treat the machine as a user too. Good testers excel at understanding a user’s mindset. So many products are better off because we tested them by putting ourselves in the shoes of human users. But users need not be human only – they can be other machines! A classic example is a go-between service that takes messages from one service, transforms it and passes it on to another service. The kind of testing you do when your end ‘user’ is a machine differs from how you would test if the end user were human. I have noticed a lot of testers have problems in this area. Most of our techniques and critiques are from a human standpoint. We need to be more conscious of what quality might look like if the end user was a machine.
I would recommend visualizing this data as an ACC model. This has the benefit of visualizing your subjective judgement of quality for each feature while also being able to show a trend over time.
YOUR TASK
If feasible, get your hands dirty and try to understand your infrastructure. Passive testers assume that knowing these details is not their job. But as the technology world progresses, you will be glad you started to mess with infrastructure earlier than later.
TIP 7:
It is hard to have confidence in your test suite when testing applications that are loosely coupled microservices. I have not been able to get any of our clients to do this but I believe that asking developers to introduce intentional bugs in specific areas (a form of ‘manual’ Mutation testing) and seeing if your test suite catches them will give you some confidence.
Aaaaaaagh! I am more confused than when I started
Good. Welcome to club. I find this kind of abstract thinking confusing too. If you try and tackle all of this at once, it will turn out to be an unholy mess. So try to break your next steps down into small, achievable pieces. If you played along, study the colour coded tables you generated. Make a checklist of items you might want to address and then prioritize them. Then work with different people (roles and teams) to figure out what are good starting points. Pick a few goals – especially ones that can add visible value. Then proceed from there.
Ask questions, point out my errors and challenge my thinking in the comments below. Thanks for reading!
I want to find out what conditions produce remarkable software. A few years ago, I chose to work as the first professional tester at a startup. I successfully won credibility for testers and established a world-class team. I have lead the testing for early versions of multiple products. Today, I run Qxf2 Services. Qxf2 provides software testing services for startups. If you are interested in what Qxf2 offers or simply want to talk about testing, you can contact me at: [email protected]. I like testing, math, chess and dogs.


[[..PingBack..]]
This article is curated as a part of #65th Issue of Software Testing Notes Newsletter.
https://softwaretestingnotes.substack.com/p/issue-65-software-testing-notes