This post is a hands-on example to help you start writing data quality checks with Soda Core. We realize a lot of our readers are fairly new to the topic of writing data quality checks. So, in this post, we will also go over some of the most common data checks you might want to implement on your structured data. We hope the ideas and the practical guide in this post help you get started with writing data quality checks at your company.
Qxf2 has noticed that writing data validation checks is becoming important skill for testers. Our experience with Great Expectations has been phenomenal, and we’ve shared our insights through blog posts. In order to expand our testing capabilities, we ventured into using Soda Core (previously known as Soda SQL) with another client in mid-2022. We successfully utilized Soda Core to validate data in a RedShift Database, which served as a crucial entry point into a complex data pipeline.
About Soda Core
Soda Core is an open-source SQL-based data auditing tool that helps users to analyze and audit their data. It is designed to be used with various databases, data warehouses, and data lakes, such as PostgreSQL, MySQL, Redshift, BigQuery, and Snowflake.
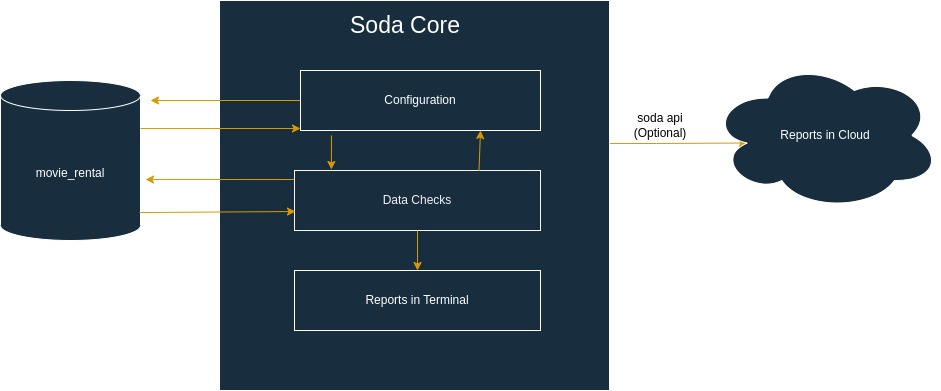
Some of the features of Soda Core include:
a) Custom tests: You can write custom tests in SQL or Python to validate the quality of our data.
b) Data profiling: Soda can generate data profiles for our tables, columns, and schemas to give you an overview of the data.
c) Automated monitoring: You can set up soda to run tests automatically on a schedule and get alerts when a test fails.
d) Data lineage tracking: Soda can track changes to our data and help you understand the impact of those changes on downstream processes.
Setup to play along with this post
We created some synthetic data for you to play long. You can find the schema and the data in the form of a SQL dump file here. Make sure that you import our data into your MySQL instance. The provided schema and data can be used to carry out practical exercises and gain experience. This will improve your understanding and abilities by enabling you to apply the ideas you have learned in a practical setting.
We are using MySQL as the data source in this post. However, if you prefer a different data source, modify this section to suit your needs. You can find easily configuration instructions in the library documentation. Additionally, make sure to set up the necessary credentials and connection parameters for your chosen data source.
Run the following command to get the Python module for soda-core that connects to MySQL.
pip install soda-core-mysql |
You are now set to play along with this post.
Getting connected to a data source
After installing Soda Core, you must make a configuration.yml file with the necessary information so that Soda Core can connect to your data source (except Apache Spark DataFrames, which does not use a configuration YAML file).
Set the value of a property that the configuration YAML file uses in a system variable that you can access from your command-line interface.
export MYSQL_USERNAME=<replace your mysql_username> export MYSQL_PASSWORD=<replace your mysql_password> |
By using the echo command, you can verify that the system can retrieve the value you entered.
echo $MYSQL_USERNAME echo $MYSQL_PASSWORD |
Set environment variable value in YAML configuration.
data_source movie_rentals: type: mysql host: 127.0.0.1 username: ${MYSQL_USERNAME} password: ${MYSQL_PASSWORD} port: 3306 database: movie_rentals |
After saving the configuration YAML file, run a scan to verify that Soda Core successfully connects to your data source.
soda scan -d movie_rentals -c configuration.yml |
Getting started with basic validations
Soda performs tests called “checks” when it scans a dataset in your data source. These checks are written using the Soda Checks Language (SodaCL) and are stored in the checks.yml file.
As you work through this section, please pay attention to the kind of data quality checks we are writing. We took some pains to make sure that we show cover of the most common kind of checks. For example, almost everyone will have at least some checks for schema, duplicate data, invalid data, null data in certain columns, etc. You can consider using similar checks on your data sources.
1. Schema Validations
a). Validate for missing column
# Checks for schema validations checks for dim_customer: - schema: fail: when required column missing: - first_name - last_name - email_id |
Now execute the schema validation check that was prepared.
soda scan -d movie_rentals -c configuration.yml check_schema_validations.yml |

Let us consider dim_customer table schema lacks an address column. We’ll look at how to validate this. We’ve included the column in the code.
# Checks for schema validations checks for dim_customer: - schema: fail: when required column missing: - first_name - last_name - email_id - address |

b) Validate Forbidden column
We can now verify if any restricted column exists in the schema. Instead of marking a test case as failed, we might issue a warning that the schema contains a banned column.
# Checks for schema validations checks for dim_customer: - schema: warn: when forbidden column present: [credit_card] fail: when required column missing: - first_name - last_name - email_id |
The test will succeed since the schema no longer has a column with that name. Therefore, we will change the schema to ensure that the test will issue a caution rather than a failure message. We will add the column “credit_card” to the schema .
ALTER TABLE movie_rentals.dim_customer ADD COLUMN credit_card VARCHAR(200); |
Run the test now, and see what happens.

Revert the change , If you prefer not to receive this warning again.
ALTER TABLE movie_rentals.dim_customer DROP COLUMN credit_card; |
c) Validate column types
Next, we’ll proceed to validate the column type within the schema.
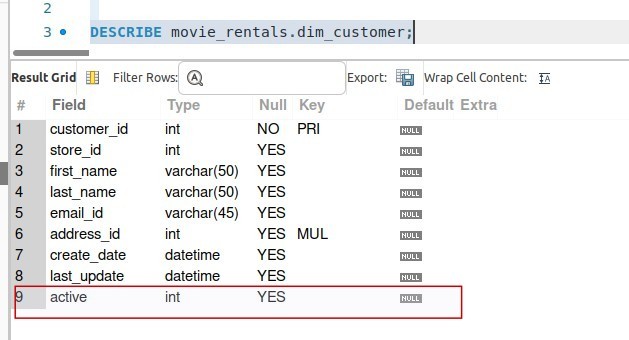
Add to checks yml for the column type validation .
# Checks for schema validations checks for dim_customer: - schema: warn: when forbidden column present: [credit_card] fail: when required column missing: - first_name - last_name - email_id when wrong column type: active: boolean |

2. Missing metrics
To identify missing values in your dataset, use a missing metric in a check.
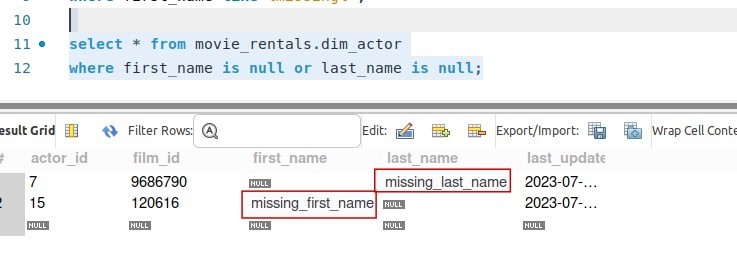
Let’s create a file named “check_missing_count_dim_actor.yml” where we will perform validation to identify any occurrences of null values in both the “first_name” and “last_name” columns.
# Checks for missing metrics checks for dim_actor: - missing_count(first_name) = 0 - missing_count(last_name) = 0 |

Based on the result set, it appears that there is a row that failed in each category. Let’s proceed to perform the query and confirm.
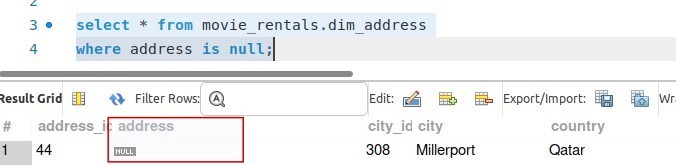
3. Missing percent
“missing percent” refers to the percentage of missing or null values in a specific column of a dataset. We are validating against the address column here . A high missing percent in a column may indicate data quality issues, which could impact data analysis and decision-making.
# Checks for missing_percent validations checks for dim_address: - missing_percent(address) > 5% |

4. Data Freshness
By performing this check, you may determine how recent the data in a dataset is by looking at the age of the row that was most recently added to a table. “freshness” will check with the current date and time . “Row count” will check the number of rows in the table. We have around 2000 rows in the table. Create a file check_data_freshness_fact_rental.yml
# Checks for data freshness checks for fact_rental: - row_count > 1000 - freshness(last_update) < 5d |

5. Duplicate count
To check the duplicate count for the film_id column, add the metric in the check_missing_count_dim_actor.yml file, which was created step 2.
# Checks for missing metrics and duplicates checks for dim_actor: - missing_count(first_name) = 0 - missing_count(last_name) = 0: missing values: [NA, n/a, '0'] - duplicate_count(film_id): warn: when between 1 and 99 fail: when > 100 |
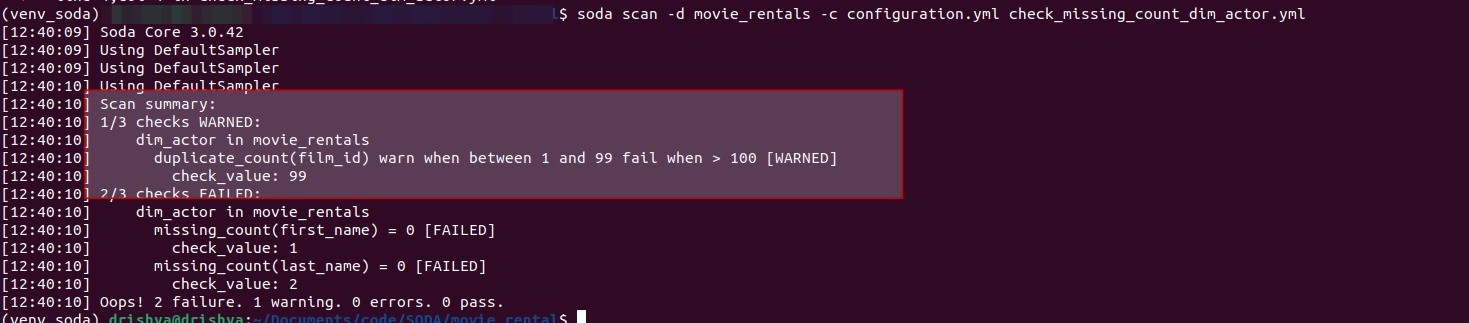
6. Invalid counts
You will validate metrics that specify which data values or formats are acceptable or unacceptable in accordance with your own business requirements.
# Checks for Invalid counts checks for dim_customer: - invalid_count(active) = 0: valid values: ['0', '1'] |
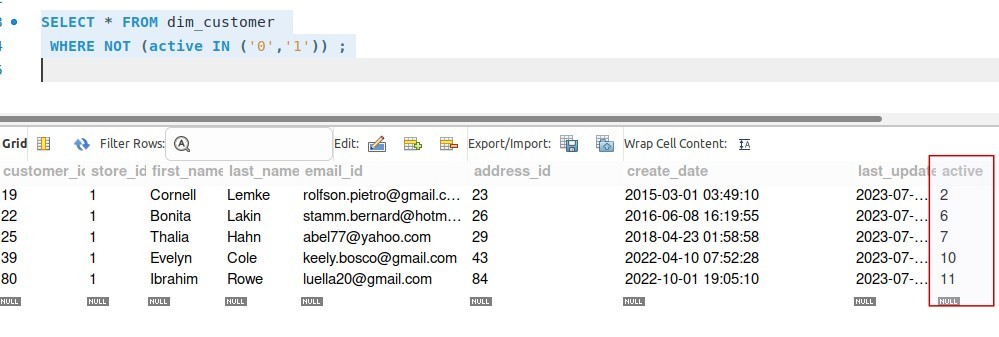
Soda Core can work together with data orchestration tools like Airflow to set up and validate data checks on a schedule. By connecting to Soda Cloud, which has various additional features, we can enhance its functionality. SodaCL also provides numerous ready-to-use checks that are easy to understand and allows us to create our own metrics and modify checks using SQL queries.
Hire technical testers from Qxf2
Hire Qxf2 for top-notch technical testers who excel in diverse testing challenges. We bring a wealth of experience to help you solve critical testing problems and provide expertise in testing modern technical stacks.

I started my career in IIIT Bangalore incubated startup company as a software engineer and soon started working on digital and e-learning solutions as QA. Later moved to Oracle as User Assistance QA Engineer and gained multiple Oracle cloud products and testing skills. Oracle gave opportunities with products, courses, and environments to explore and enhance testing skills. Now joined Qxf2, to explore in testing perspective. I believe Quality means doing it right, even when no one is looking. A number of bugs are not evaluating the product, the quality of the bug also matters. I love cooking, reading, and DIY crafts.

