In previous blog, we tested OpenAI Whisper for English language with different accents and observed it did great job. We also provided details about how we generated audios, setup and test details. In this blog, we attempted to test OpenAI Whisper’s capability to transcribe and translate Indian Languages.
At Qxf2, our teammates work from different regions of India, and everyone capable of reading, writing, and speaking 2 to 3 different languages. With their help, we decided to test the following Indian languages: Hindi, Kannada, Telugu, Marathi, Tamil, Malayalam, and Bengali. Team members generated audio files in their own regional language by using online text to speech tools like Narakeet, textmagic, etc. Some of the teammates also recorded their own and family members’ voices. We generated transcriptions and translations of each audio file and came up with the following comments on translation and transcription.
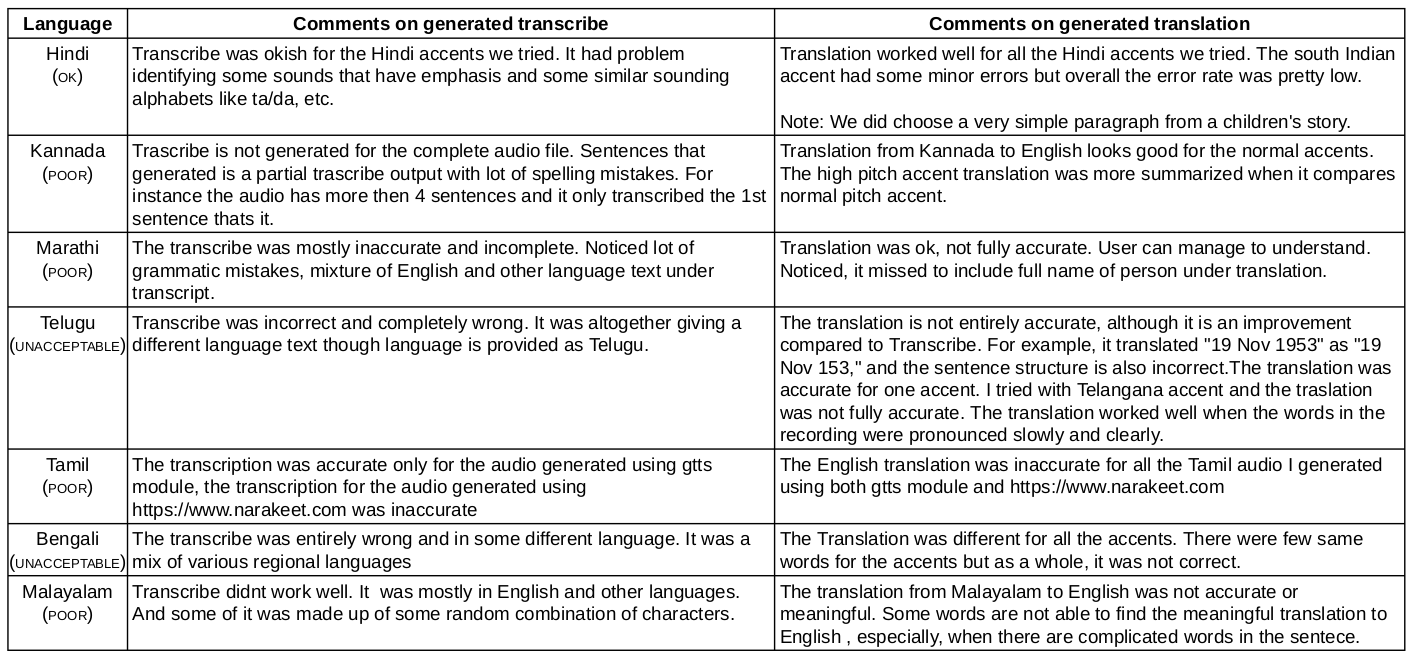
You can look at all generated audio files along with translations and transcriptions here. You can also try out OpenAI Whisper’s support for your language by generating audio files and following the steps below to generate transcriptions and translations.
Generate transcribe and translation:
Please look at our previous blog to set up OpenAI Whisper locally. Once you are done with that run the below commands to generate transcribe and translation.
1. Command to generate transcribe:
whisper --output_format txt --model medium --task transcribe <audio file> |
Note: During the first run of the above command, OpenAI whisper downloads the medium model, which is approx 1.5 GB.
The above command uses medium model to generate the transcription output in a txt file. You can switch to another format by changing the output_format option. Here, we used the medium model to generate the transcription as it is recommended for non-English languages.
Sometimes, we noticed that Whisper fails to auto-detect the correct language as it guesses the language based on the first 30 seconds of audio. If you notice such behavior, you can pass the audio language along with the language option like --language Kannada
Additionally, we noticed that this command took 10+ minutes to generate transcriptions for 30 seconds of audio.
2. Command to generate translate:
whisper --output_format txt --model medium --task translate <audio file> |
Above command uses the medium model to generate the audio file translation in English. For translation, we need to use the task option; by default, this option is set to transcribe.
Common Observations:
1. All of us noticed that generating a transcript with the medium model takes a long time.
2. Sometimes the transcribe generates in another language even after explicitly providing the language in the command. Most of us noticed that the transcribe contains some English words, question marks in between the sentences, and sometimes the transcribe was incomplete and in a different language. Look at the image below. 
3. For a few audios, we noticed that the transcription is different for each run. Look at the above image: all 3 runs show different outputs for the same audio file.
4. Comparatively, generating a translation takes less time than generating a transcription. And in most of our cases, the translation is better than the transcription.
Conclusion:
We tested OpenAI Whisper with seven Indian languages. The audio files were generated by our colleagues. We noticed Whisper is not fully ready for Indian languages yet.
Hire Qxf2!
Qxf2’s software testers specialize in testing the often overlooked technical core of your product. Our approach goes beyond traditional test automation, allowing us to identify critical quality aspects specific to your application and conduct thorough testing. With a preference for small teams and early stage products, we are passionate about delivering exceptional testing services. To get in touch with us, simply fill out this simple form.

I love technology and learning new things. I explore both hardware and software. I am passionate about robotics and embedded systems which motivate me to develop my software and hardware skills. I have good knowledge of Python, Selenium, Arduino, C and hardware design. I have developed several robots and participated in robotics competitions. I am constantly exploring new test ideas and test tools for software and hardware. At Qxf2, I am working on developing hardware tools for automated tests ala Tapster. Incidentally, I created Qxf2’s first robot. Besides testing, I like playing cricket, badminton and developing embedded gadget for fun.


{kind=link}
Which whisper model is best to transcribe hindi audio. I have tried large v2 and large. Its not perform better. Is there any alternate model available for hindi language
Hi,
We had used only the medium model for our work, but you can try using this model vasista22/whisper-hindi-large-v2, this is a large v2 model fine tuned for Hindi.