A colleague of mine tests a product that helps big brands target and engage Hispanic customers in the US. As you can imagine, they use a lot of survey data as well as openly available data to build the analytics in their product. We do test the accuracy of the underlying algorithms. But the algorithms used are only going to be as good the underlying data itself. So, a big and often ignored challenge for testing such applications is the verifying the validity of the underlying data itself.
I set out to see if I could help in this regard. We could make sure the Hispanic and Latino population data displayed in the application was somewhat similar to the most recent census data available. This page on Wikipedia had the data I wanted. The rest of this post outlines the two methods I used to scrape the Wikipedia table using Python.
Why this post?
As testers, we sometimes need real (or realistic) data for testing. But it is really hard to find data in the format you need. Often, we need to go to the websites such as Wikipedia , extract the data and then do the formatting we need. Wikipedia tables have proven to be an excellent source of data for us. So I thought I would share a couple of methods to scrape Wikipedia tables using Python.
Overview
Generally speaking, there are two basic tasks for scraping table data from a web page. First, get the HTML source. Second, parse the HTML to locate the table data. The key to scraping is looking at the HTML, understanding the page structure and figuring out how you want to pull the data.
We are going to scrape the table data (image below) from the Wikipedia web page for Hispanic and Latino population in USA. This data includes States/Territory, population growth percentage details etc.,
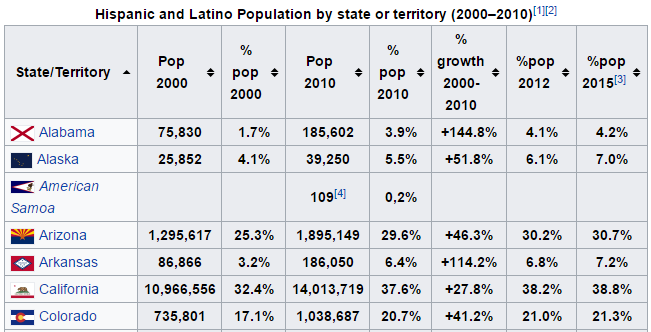
Now that we know where our data is, we can start our coding. In this post I will show two methods to scrape the data:
a) Method 1: Use Wikipedia module and BeautifulSoup
b) Method 2: Use Pandas library
Note: If you have the option, I recommend the Pandas library because I found it magical!
Method 1: Use Wikipedia module and BeautifulSoup
Wikipedia module has functions for searching Wikipedia, getting article summaries, getting data like links and images from a page, and more. However, we couldn’t find a way to scrape table data using Wikipedia library. That’s why we used the Wikipedia module in combination with BeautifulSoup.
We used the Wikipedia library to search and get HTML source. We used Beautifulsoup to parse the HTML table. You will notice one difference between our implementation and other online solution: our implementation treats the table as a tree rather than as an orderly structure of tr and td elements.
import wikipedia, re from BeautifulSoup import BeautifulSoup def get_hispanic_population_data(): "Get the details of hispanic and latino population by state/territory" wiki_search_string = "hispanic and latino population" wiki_page_title = "List of U.S. states by Hispanic and Latino population" wiki_table_caption = "Hispanic and Latino Population by state or territory" parsed_table_data = [] search_results = wikipedia.search(wiki_search_string) for result in search_results: if wiki_page_title in result: my_page = wikipedia.page(result) #download the HTML source soup = BeautifulSoup(my_page.html()) #Using a simple regex to do 'caption contains string' table = soup.find('caption',text=re.compile(r'%s'%wiki_table_caption)).findParent('table') rows = table.findAll('tr') for row in rows: children = row.findChildren(recursive=False) row_text = [] for child in children: clean_text = child.text #This is to discard reference/citation links clean_text = clean_text.split('[')[0] #This is to clean the header row of the sort icons clean_text = clean_text.split(' ')[-1] clean_text = clean_text.strip() row_text.append(clean_text) parsed_table_data.append(row_text) return parsed_table_data #----START OF SCRIPT if __name__=="__main__": print ('Hispanic and Latino population data in the USA looks like this:\n\n') hispanic_population_data = get_hispanic_population_data() for row in hispanic_population_data: print ('|'.join(row)) |
Let’s take a look at the code to see how this all works:
Step1: Get the HTML source
We created a function and set up wiki_search_string, wiki_page_title, wiki_table_caption variables. By using wikipedia.page() method, we pull the HTML source based on the page title. The function returns the HTML of the page in the my_page variable.
Step2: Identify the table
Next, we pass this HTML to BeautifulSoup which turns it into a well-formatted DOM object. We are trying to extract table information about Hispanic and Latino Population details in the USA. With the help of BeautifulSoup’s find() command and a simple regex, we identify the right table based on the table’s caption.
Step3: Extract the table data
Now that we identified the table that we need, we need to parse this table. We pull all the tr elements from the table. We use BeautifulSoup’s findChildren(recursive=False) method to find the immediate children of each row. Note that we do not bother identifying the columns using the td. This is because the table is somewhat unstructured and contains images, links, line breaks and th elements sprinkled in a few different places. In the above code, we have done some data cleaning to clean up few citation links and icons.
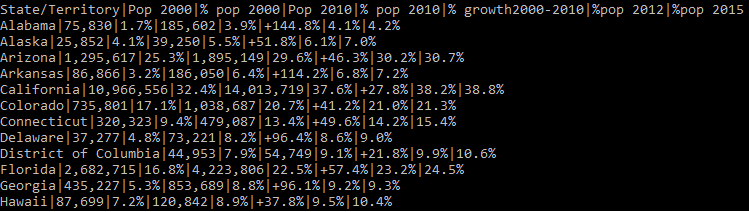
Great! Once you execute this code you should see below output –
Method 2: Use Pandas library
I suspected that there might be an easier way to do this sort of thing. And my instinct was right. The other way is, using Pandas’ read_html(). You can read HTML tables into a list of DataFrame objects. It finds the table element, does the parsing and creates a DataFrame. This function searches for table elements and only for tr and th rows and td elements within each tr or th element in the table. Below is a sample code to pass the HTML to pd.read_html().
import pandas as pd import wikipedia as wp #Get the html source html = wp.page("List of U.S. states by Hispanic and Latino population").html().encode("UTF-8") df = pd.read_html(html)[0] df.to_csv('beautifulsoup_pandas.csv',header=0,index=False) print (df) |
The output is –
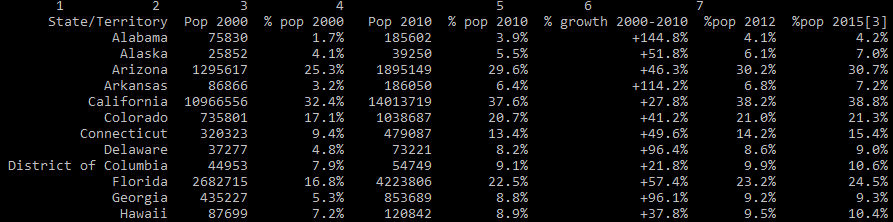
After you call this function, you notice Pandas automatically fills in NaNs (Not a Number) for empty cells. I came away really impressed with how easy Pandas made parsing a relatively hard-to-parse table.
Note: This data may not be tidy enough or in the format needed by your project. You need to make it tidy before using it. You can refer to my other post Cleaning data with Python for some tips and tricks on cleaning data and restructuring the data.
If you are a startup finding it hard to hire technical QA engineers, learn more about Qxf2 Services.
References:
I hope you have found this post useful for web scraping with Python. Here are few references I found useful:
1. Data Scraping: Good article explaining about how to get data from the web, Scraping websites, tools that help to scrape.
2. Using Pandas for Data scraping
3. Wikipedia Table data Scraping with Python and BeautifulSoupThis article shows you another way to use BeautifulSoup to scrape Wikipedia table data.

I am an experienced engineer who has worked with top IT firms in India, gaining valuable expertise in software development and testing. My journey in QA began at Dell, where I focused on the manufacturing domain. This experience provided me with a strong foundation in quality assurance practices and processes.
I joined Qxf2 in 2016, where I continued to refine my skills, enhancing my proficiency in Python. I also expanded my skill set to include JavaScript, gaining hands-on experience and even build frameworks from scratch using TestCafe. Throughout my journey at Qxf2, I have had the opportunity to work on diverse technologies and platforms which includes working on powerful data validation framework like Great Expectations, AI tools like Whisper AI, and developed expertise in various web scraping techniques. I recently started exploring Rust. I enjoy working with variety of tools and sharing my experiences through blogging.
My interests are vegetable gardening using organic methods, listening to music and reading books.


Hi can you give me a clue how to extract these types of data from a result sheet. myself manu working in pvt college i have to do result analysis for the college. taught of programming it. can you please help in this regard
Register No. 15BGS85130 Name :ABHISHEK K ! !
Paper Code : SDC6SB SM1C61 SM1C62 SM1P61 SM1P62 SP1C61 SP1C62 SP1P61 SP1P62 SS2C61 SS2C62 SS2P61 SS2P62 ! !
Total Marks: 25 7 0 A A 5 4 A A 0 3 A A ! 44 !
I.A.Marks : 15 10 2 0 0 15 15 8 8 4 3 0 0 ! 80 !RE-
! !APPEAR
———————————————————————————————————————————-
Register No. 15BGS85131 Name :ANEESH R FIRST CLASS EXEMPLARY ! !
Paper Code : SDC6SB SM1C61 SM1C62 SM1P61 SM1P62 SP1C61 SP1C62 SP1P61 SP1P62 SS2C61 SS2C62 SS2P61 SS2P62 ! !164
Total Marks: 45 56 41 35 31 65 55 32 32 43 37 34 34 !540 !8.2GPA
I.A.Marks : 25 26 25 12 15 25 24 14 14 24 26 15 15 !260 !A+
! !GRADE
———————————————————————————————————————————-
Register No. 15BGS85132 Name :ARCHANA K FIRST CLASS EXEMPLARY ! !
Paper Code : SDC6SB SM1C61 SM1C62 SM1P61 SM1P62 SP1C61 SP1C62 SP1P61 SP1P62 SS2C61 SS2C62 SS2P61 SS2P62 ! !167
Total Marks: 43 61 59 35 35 34 46 35 35 52 40 35 35 !545 !8.35GPA
I.A.Marks : 25 29 22 15 15 26 26 15 15 30 30 15 15 !278 !A+
! !GRADE
———————————————————————————————————————————-
Register No. 15BGS85133 Name :KIRAN U R ! !
Paper Code : SDC6SB SM1C61 SM1C62 SM1P61 SM1P62 SP1C61 SP1C62 SP1P61 SP1P62 SS2C61 SS2C62 SS2P61 SS2P62 ! !
Total Marks: 44 12 5 34 31 8 * 35 35 34 41 33 33 ! !
I.A.Marks : 27 21 21 15 14 23 23 15 15 20 19 15 15 ! !N.P.
! !
my email id is [email protected]
Hello,
I’m new with python and I’m trying to extract some information about currencies but in Portuguese and Spanish wikipedia pages, to try to use for it for text mining. I tried what you did but I don’t have the right page.
Hi Isabaala ,
Can you provide us the links of the pages you are trying to scrape and what output are you currently getting
Thank You