Did you know you can scrape data from webpages without writing a single line of code? In this post, we will talk about a tool called Octoparse. We used Octoparse to scrape data from a list of URLs, without any coding at all.
Data is valuable and it’s not always easy to get the correct data from the web sources because all websites have different templates and designs. There are various ways to acquire data from websites of your preference. Crawlers, like Google’s, look at webpages and follow links on those pages. They go from link to link and bring data about those webpages back to Google’s servers. This can help us find what we are looking for in a matter of seconds but the data is not structured and hence can’t be used for analysis.
Why this post?
We recently came across a automated web crawler called Octoparse. Using Octoparse, you can develop extraction patterns and define extraction rules which would tell Octoparse which website is to be opened, how to locate the data you plan to scrape and what kind of data you want etc. Octoparse can scrape any data visible on a webpage. Octoparse has many built-in tools and APIs to crawl and re-format the extracted data using a user-friendly point & click UI.
In this post, we will talk about Octoparse and different extraction rules which we configured to scrape our blog. We’ll extract meta-data about the posts published on this blog. We managed to do that with Octoparse without any coding at all. Below is the list of items that we are going to cover in this post
- Octoparse Overview
- Installation
- Features
- Setting up basic information
- Workflow Design
- Extraction Options
- Example Usecase
1. Octoparse Overview
Octoparse is a Windows application and is designed to harvest data from both static and dynamic websites. The software simulates human actions to interact with web pages. To make data extraction easier, Octoparse features filling out forms, entering a search term into the text box, etc. You can run your extraction project either on your own local machine (Local Extraction) or in the cloud (Cloud Extraction). Octoparse’s cloud service (available only in paid editions) is useful for fetching large amounts of data to meet large-scale extraction needs. There are various export formats of your choice like CSV, Excel formats, HTML, TXT, and database (MySQL, SQL Server, and Oracle).
2. Installation
Here is the link to Download Octoparse. Follow these steps to install Octoparse.
- Download the installer and unzip the downloaded file
- Double click on the setup.exe file
- Follow the installation instructions
- Signup and Log in with the Octoparse account for free (Free plan offered is with unlimited pages to scrape and unlimited storage)
3. Features
The following are the key features of Octoparse.
Point-and-Click Interface – Octoparse applies machine learning algorithms to accurately locate the data at the moment you click on it. Simply point and click web elements, and Octoparse will identify all the data in a pattern and extracts any web data automatically. No coding is required for most websites.
Deal with dynamic and static websites – Octoparse allows to easily scrape behind a login, fill in forms, input search terms, click through infinite scroll, switch drop downs. Capture anything from webpages like text, link, image URL, or html code.
Cloud service (Paid editions) – Octoparse’s Cloud platform allows for 6 to 14 times faster data extraction, running the extraction task 24/7. Data is scraped and stored in the cloud and accessible from any machine.
Automatic IP Rotation – Octoparse Cloud service is supported by hundreds of cloud servers, each with a unique IP address. When an extraction task is set to execute in the Cloud, requests are performed on the target website through various IPs, minimizing the chances of being traced and blocked.
Schedule Extraction – Cloud Extraction enables a task to be scheduled to run at any specific time of the day, week or month.
Store or save your data – Access the extracted data via Excel or API, or export to your own database. Connect with Octoparse API and have the data delivered automatically to your own systems. Get data, export data, publish data, or use it in any creative way via automatic integration.
Built-in tools – Octoparse supports many built in tools like XPath generator, XPath tool,
RegEx: Built-in regular expression tool.
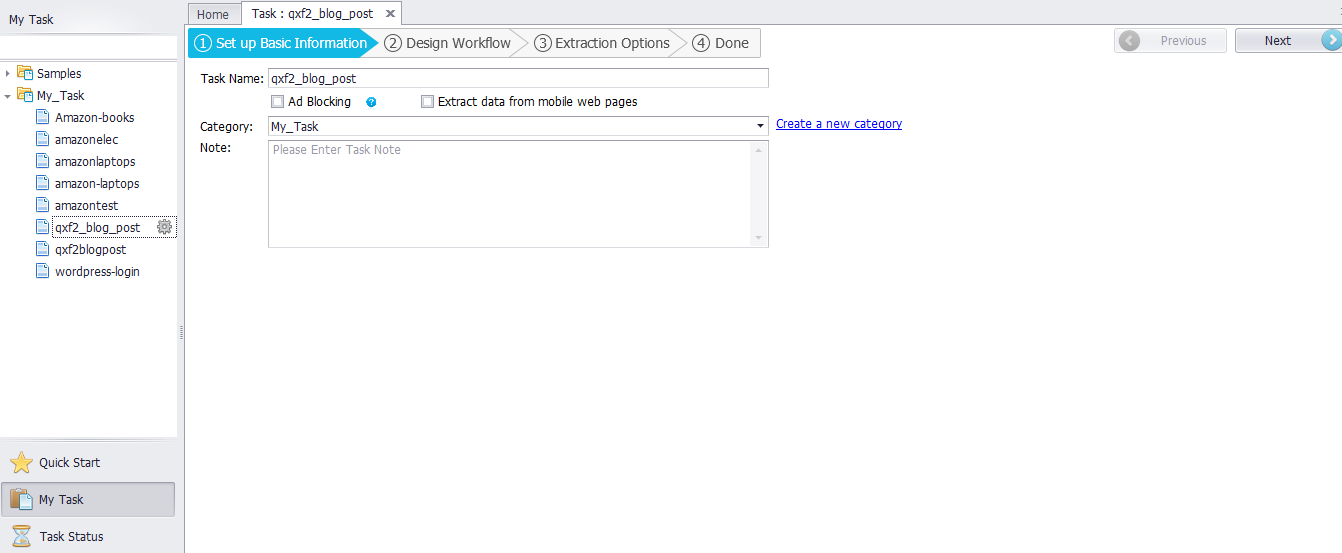
4. Setting up basic information
Currently, Octoparse supports two modes – the Wizard mode and the Advanced mode. You can choose one of these two modes to start an extraction task. Wizard mode is more suitable for beginners. You can fetch data from simple webpages by just following the instructions step by step to configure your own task. With advanced mode, you can easily deal with any complex page structure. Use the Navigation panel to quickly find and open your tasks. In the Navigation panel, you can quickly start a task, find a task, open and manage a task, check the task status etc.,
5. Workflow Design
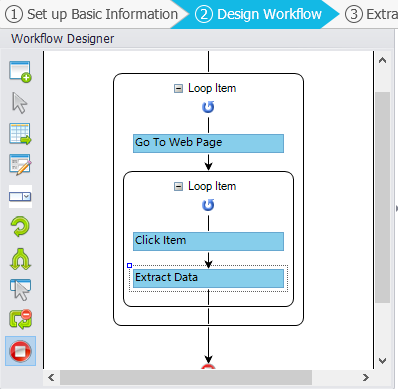
Visual workflow designer is the visual operation pane provided in Octoparse which enables a user to create workflows with “point” and “click”. Similar to many other automatic scrapers, Octoparse works in a way that simulates a real person interacting with the webpages. The extraction rule is one of the most important features of Octoparse. You can configure the rule to paginate, to scrape a website behind a login, to collect data from webpages loaded with AJAX, to scrape a website with infinite scrolling.
You can drop task actions to configure the extraction rule. Task Actions in Workflow Designer include Open webpage, Add Item, Add loop, Paginate, Extract Data Actions.
6. Extraction Options
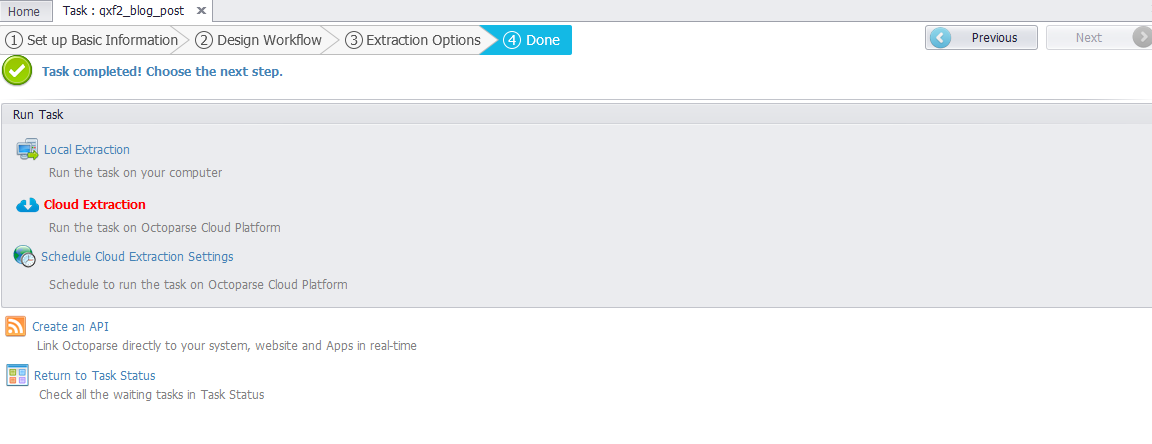
Once the Task is completed, you can choose the Local extraction or Cloud Extraction. The data extracted will be shown in the data extracted pane. The configured rule of the task is seen in the right pane. You can also check out the built-in browser to see if the task runs as expected. Once the Extraction is completed you can export the results to Excel files, or other formats and save the file to the computer(Please refer below example for Local Extraction)
When you choose Cloud Extraction, Octoparse would automatically extract any data you want with high speed and productivity. Cloud Extraction means data extraction tasks running in the cloud. You need to configure a rule and upload it to our cloud platform. Then your task will be reasonably assigned to one or several cloud servers to extract data simultaneously via central control commands.
7. Example Usecase
Now that we got familiar with Octoparse features, rules, task actions, let’s try it with an example. In this post, we will show you how we used Octoparse and scraped metadata about our blog posts. We scraped some posts from our WordPress website. In this example, there are two sections for getting the real-time dynamic data using Octoparse – Make a scraping task and Local Extraction to save the report in a .xlsx file.
The website URL used in this example is here
The data fields include Title, Author, Date, Status and Commentscount..
Section 1 – Make a scraping task
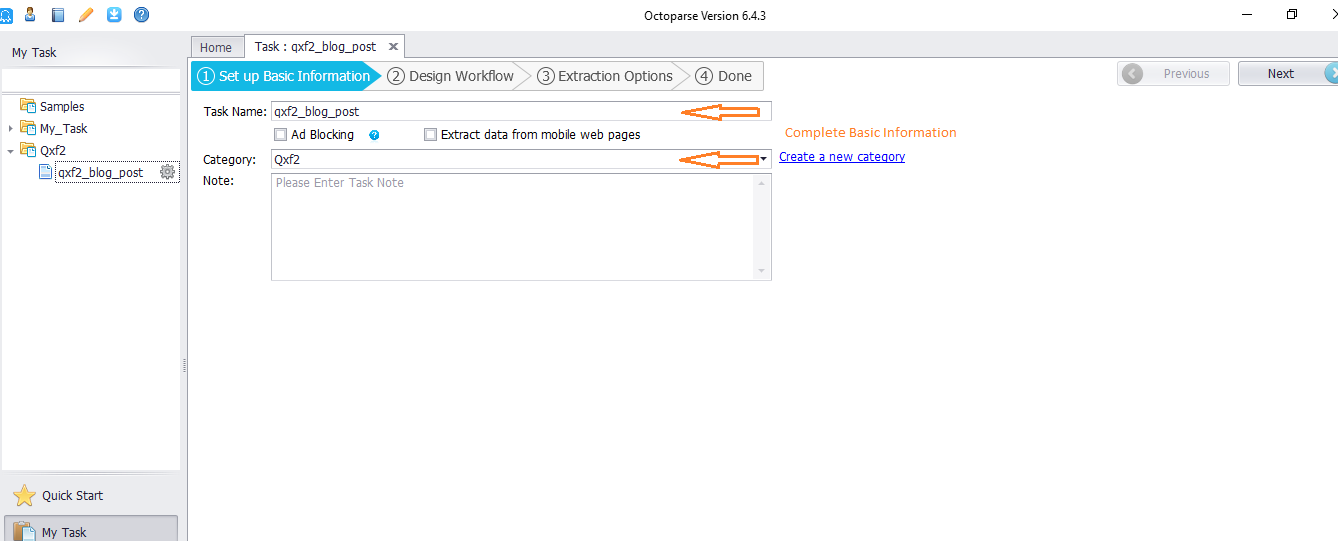
Step 1 – Set up basic information.
Click “Quick Start” ➜ Choose “New Task (Advanced Mode)” ➜ Complete basic information ➜ Click “Next”
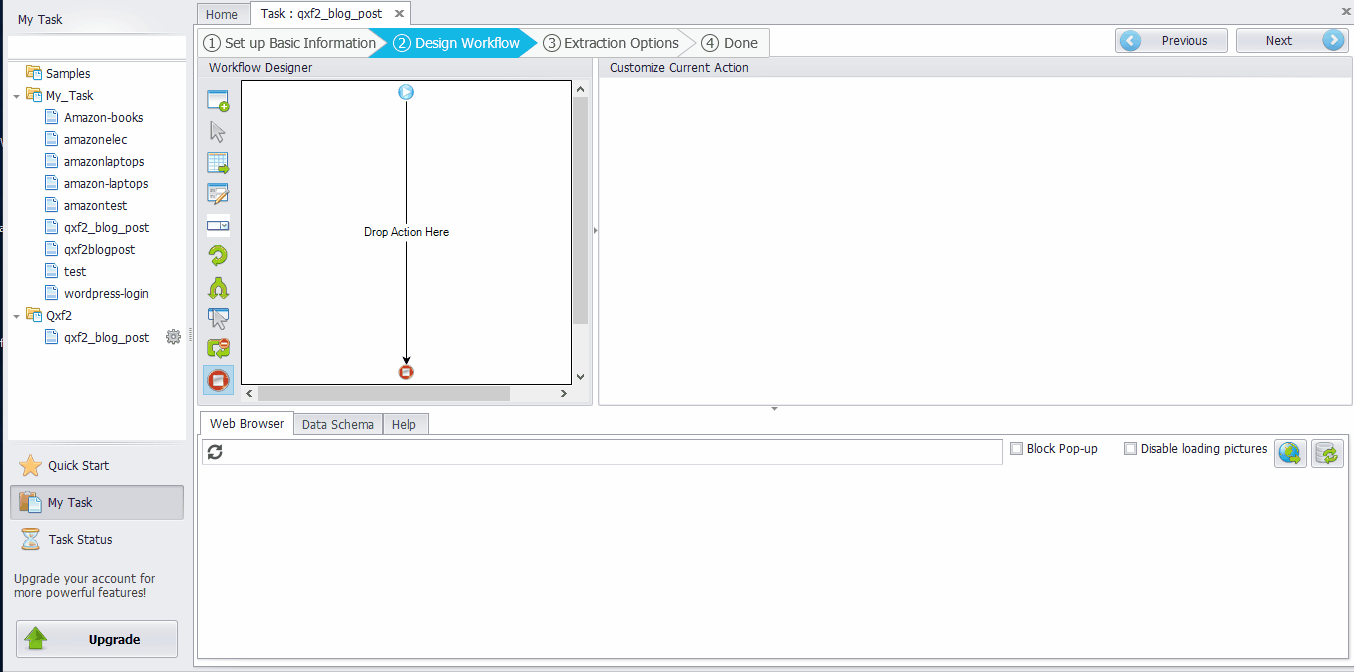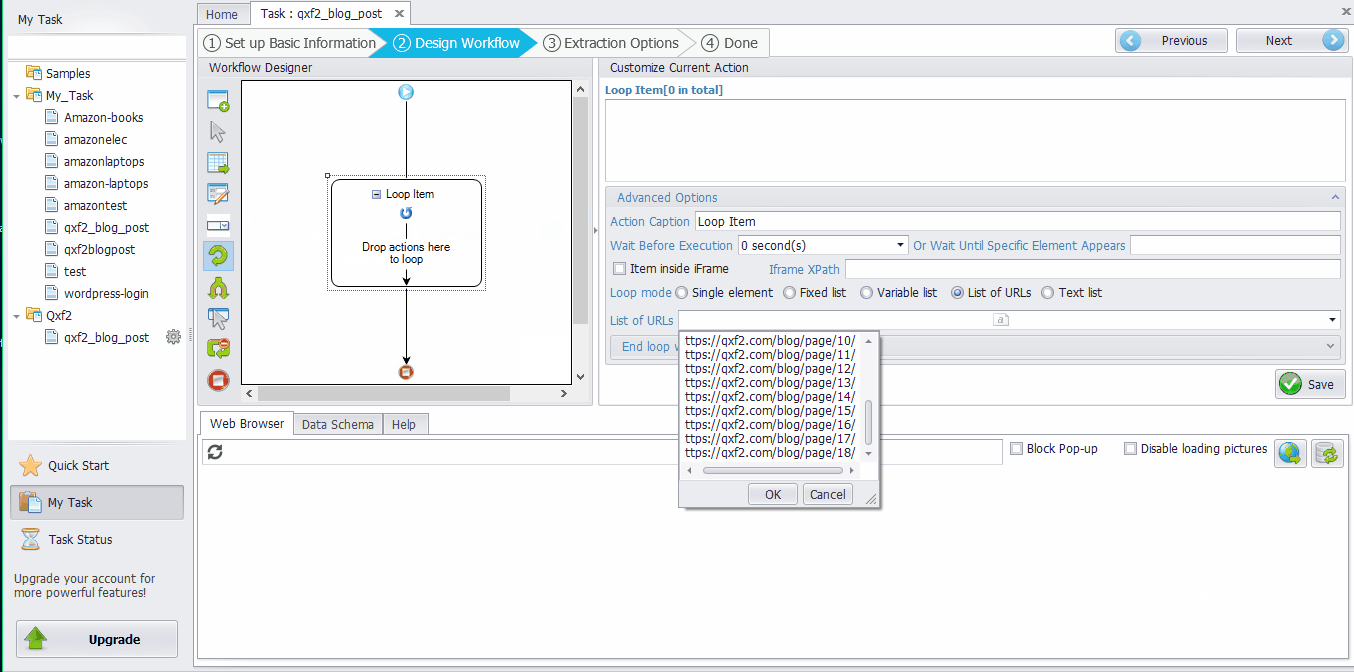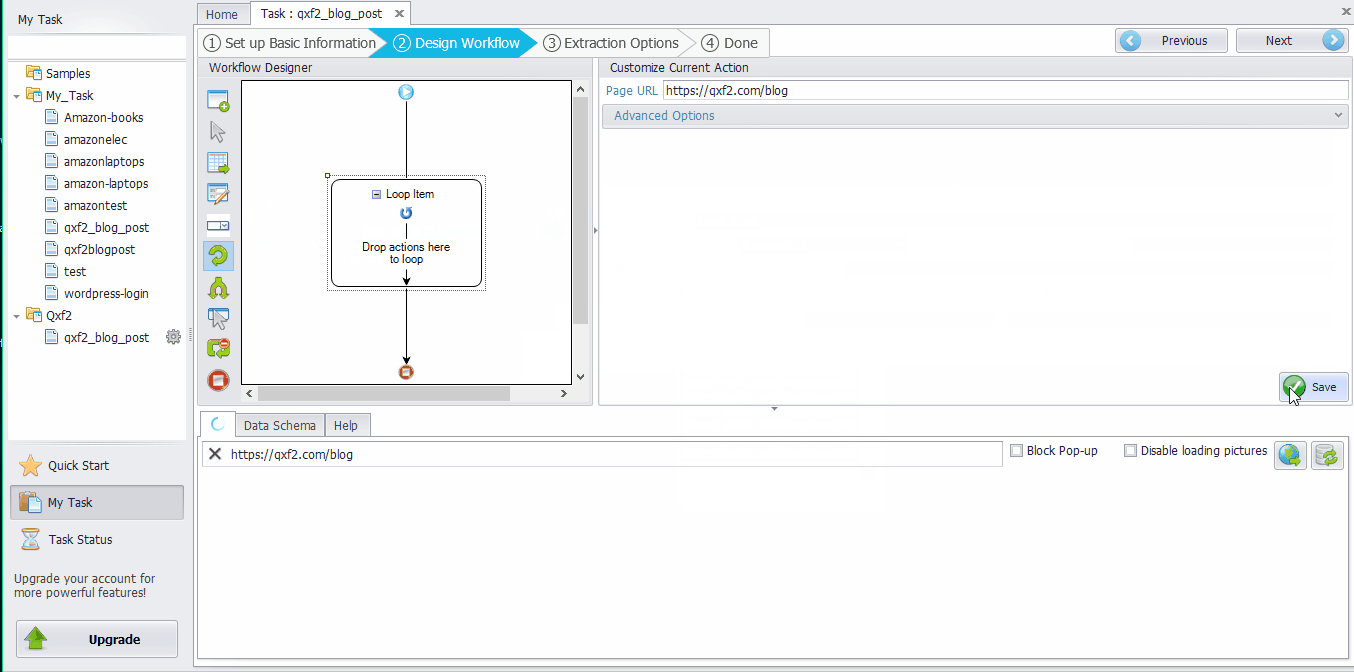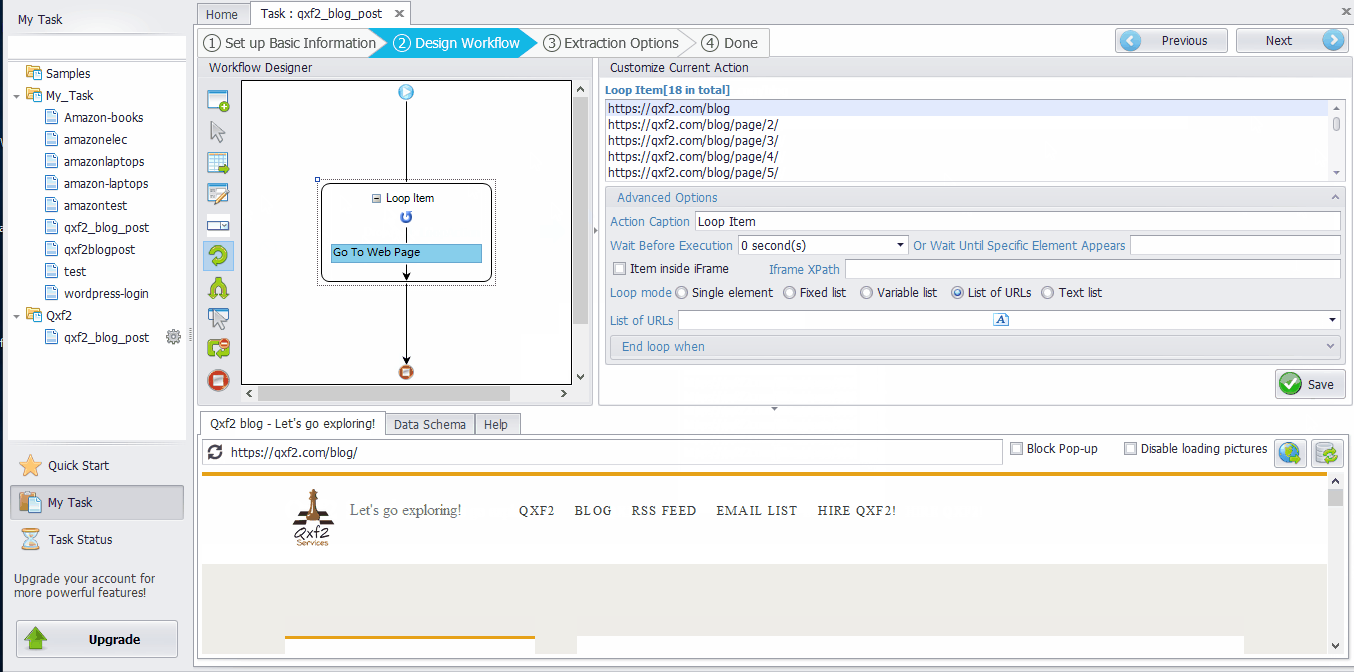
Step 2 – Use the “List of URLs” input box to realize the functionality of pagination. Pagination is used when the content we want to scrape spans over different pages of a website. Octoparse mimics human browsing behaviors, so just as you would click to the next page as you browse through a website, Octoparse does the same when you use pagination feature. Follow the steps below:
Drag the “Loop Item” box into the workflow ➜ Click the “List of URLs” input box in the Advanced Options and paste the target webpage URLs that you want to scrape from. ➜ Click the “OK” button. ➜ Click the “Save” button.
(URL of the example: https://qxf2.com/blog/)
Step 3 – Creating a list of items and loop the process. Below are the steps
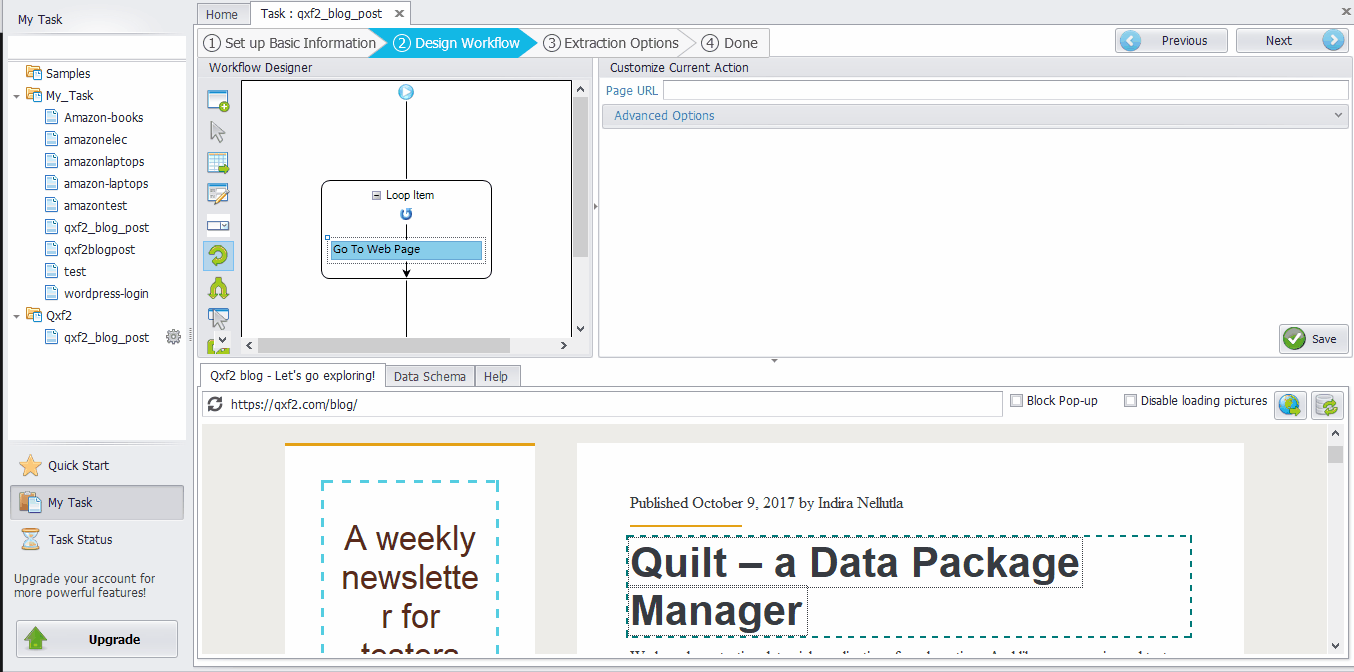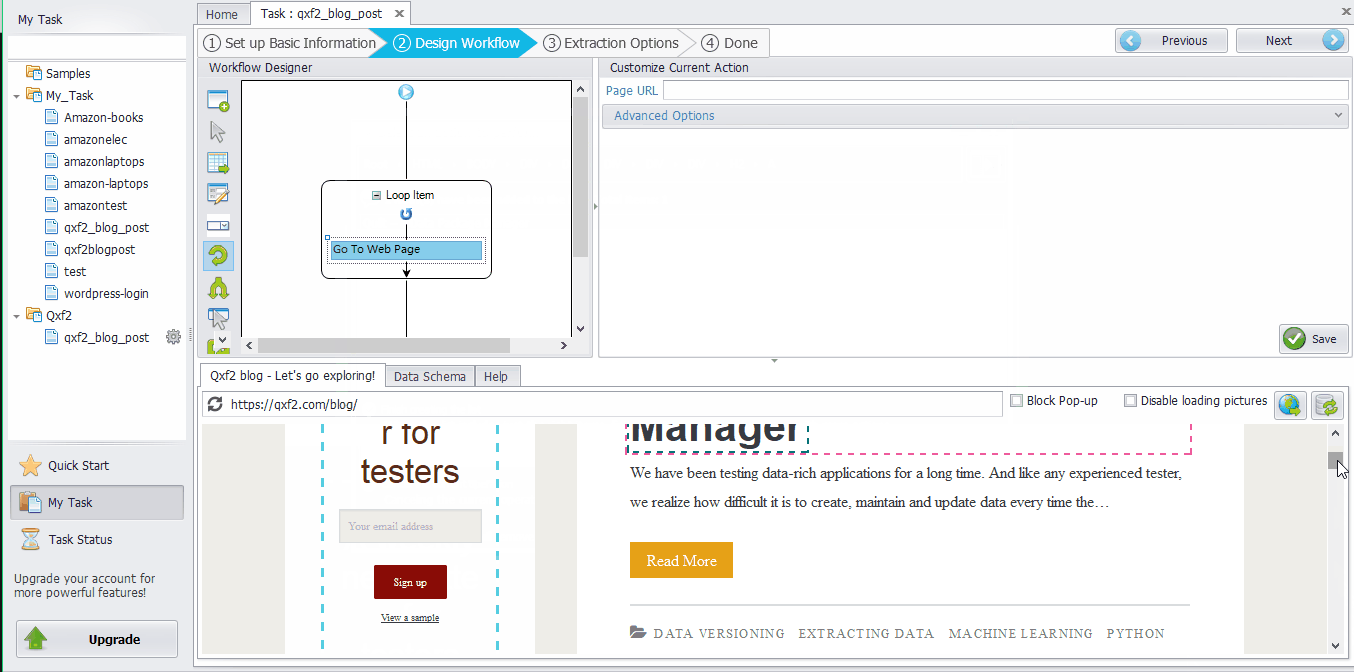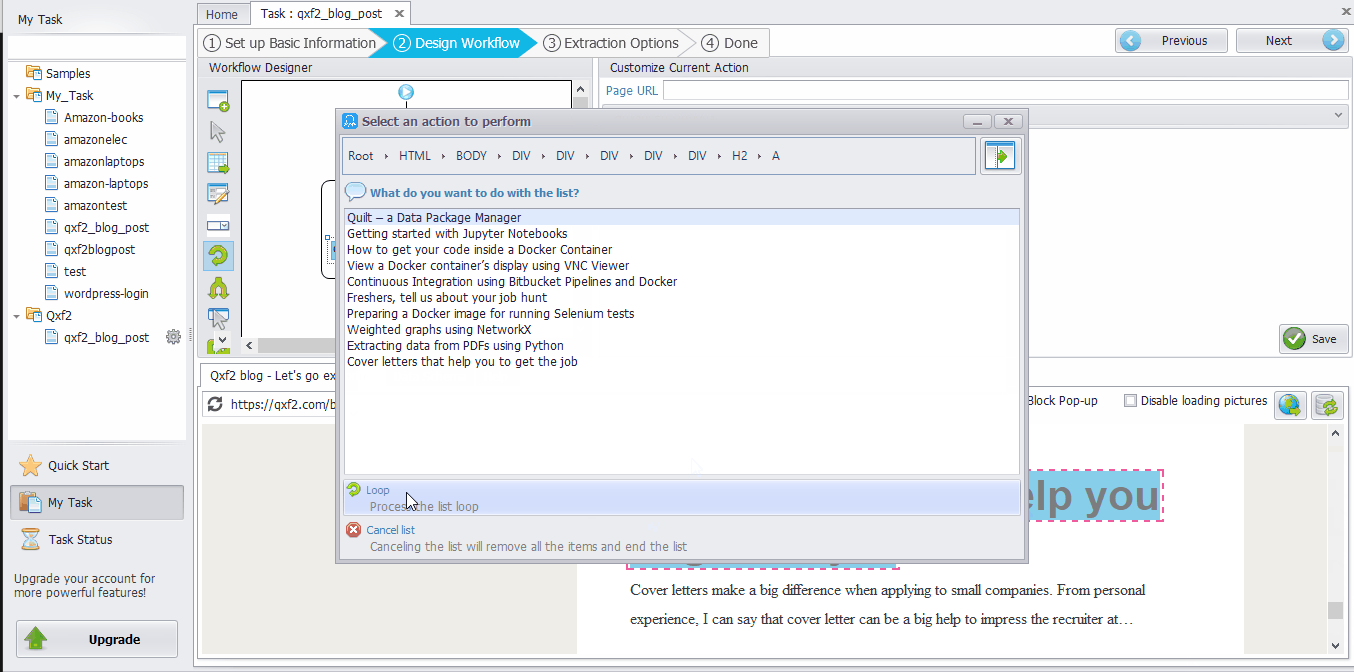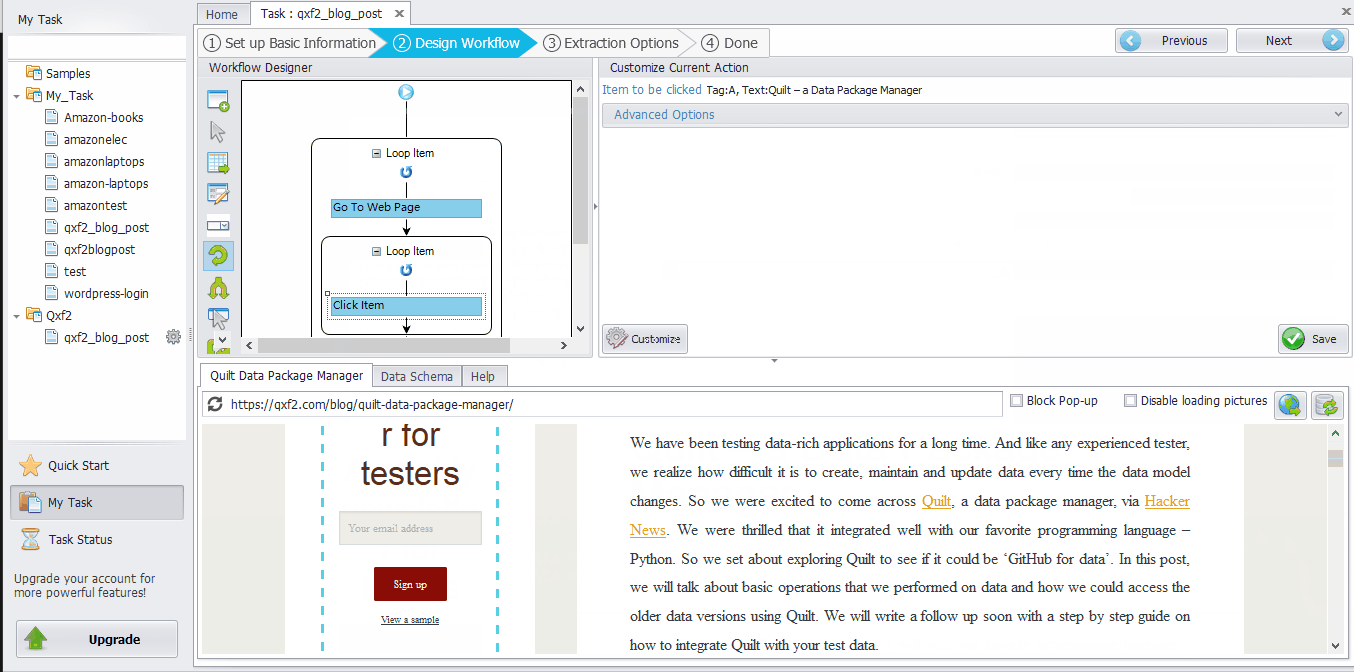
Right-click the first post ➜ Create a list of target areas with a similar layout. Click “Create a list of items” ➜ “Add current item to the list”.
Right-click the last post. ➜ Click “Add current item to the list” again (Now we get all the posts with similar layout) ➜ Click “Finish Creating List” ➜ Click “loop” to process the list for extracting the content of the posts.
Step 4 – Extract the contents that you need from the posts
Click the Title of the post ➜ Select “Extract text”. Similarly, other contents can be extracted in the same way. All the content will be selected in Data Fields. ➜ Click the “Field Name” to modify. Then click “Save”. For this example, we have extracted data fields Title, Author, Date, Status and Commentscount..
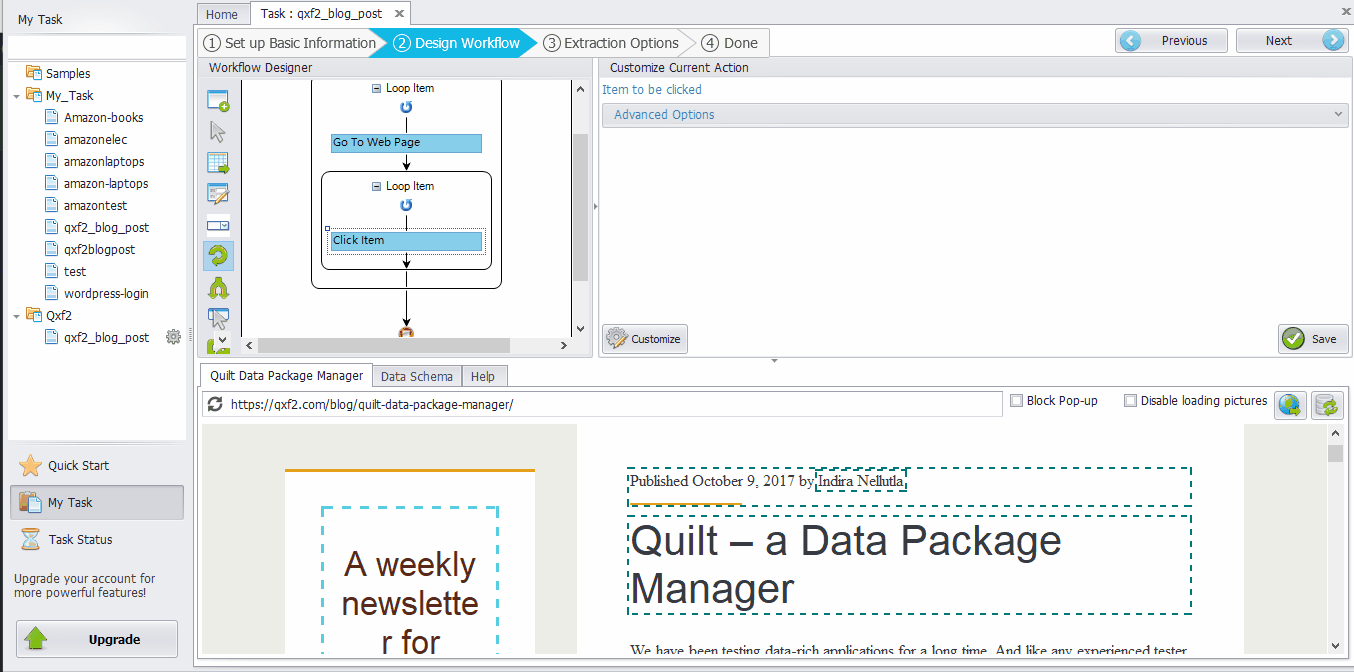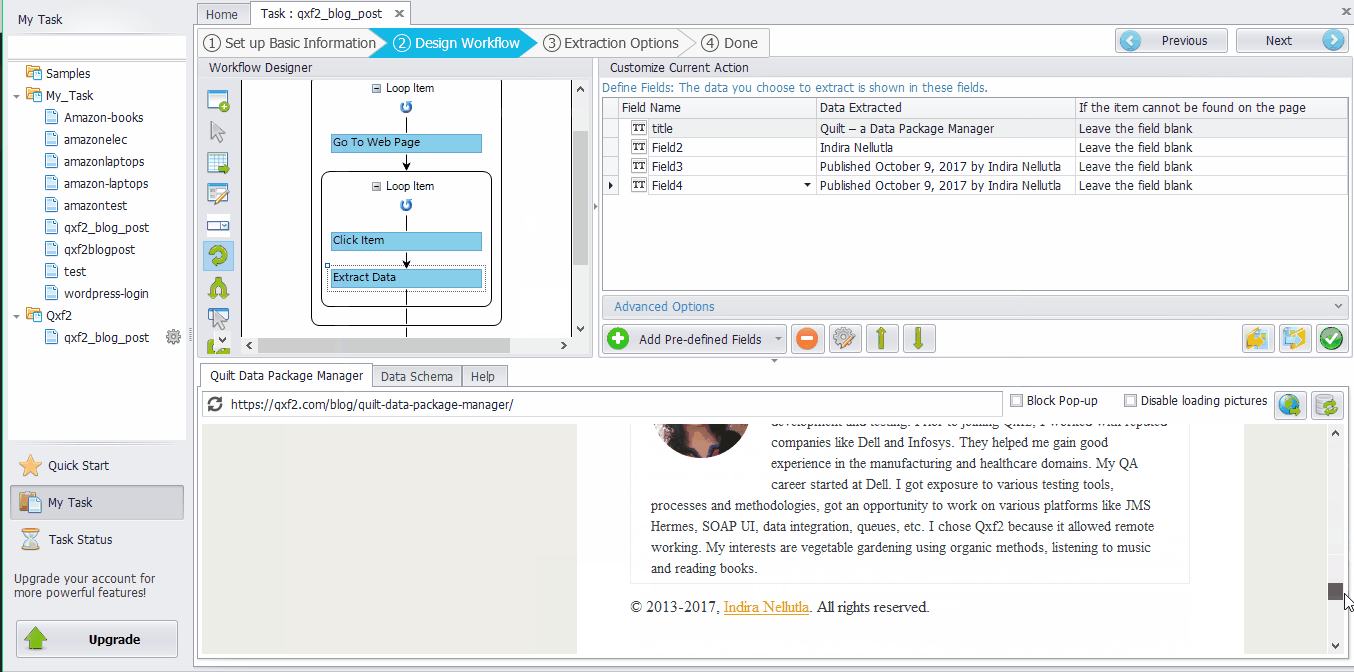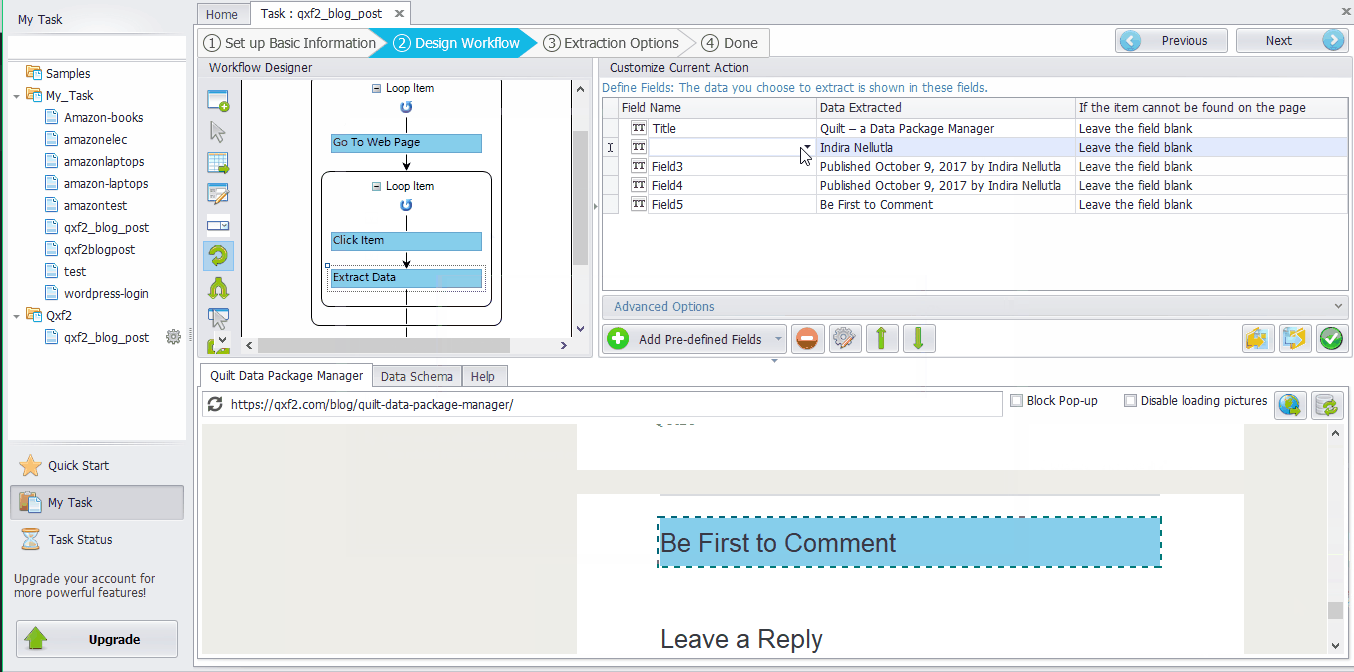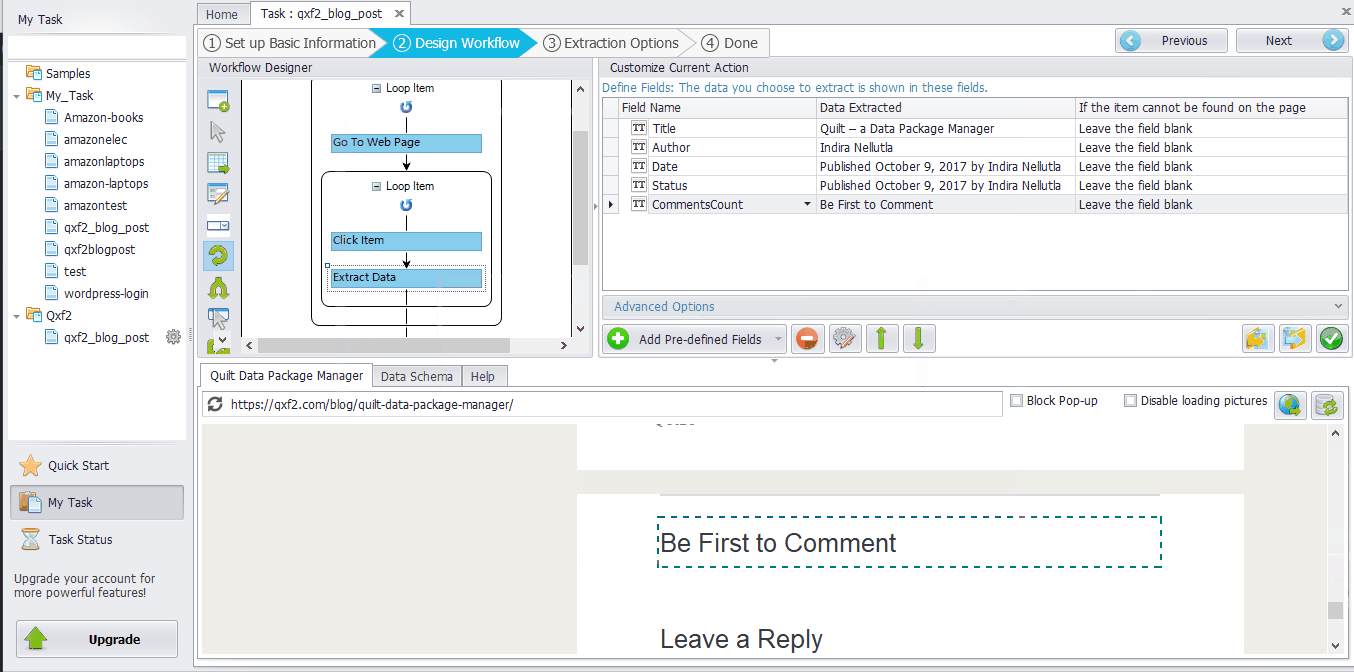
If you look at the extracted fields, the Date field contains the format “Published October 27, 2017 by Author Name” It consists of Date and Publish details along with the Author details. But for our requirement we need only the Date value for e.g., ‘October 27, 2017’. Data re-format in Octoparse is a useful tool which helps to re-format the extracted data if it is not in the form you want. Octoparse mainly has 8 different functions(Replace, Replace with a regular expression, Match with a regular expression, Trim spaces, Add prefix, Add suffix, Re-format extracted date/time and Html transcoding) to re-format the data.
If you know how to write a regular expression, you could create the Regular Expression to match the information you want directly. If you don’t know how to write a regular expression, you could try a built-in Tool “RegEx Tool” as shown below. Octoparse provides an inbuilt regex generator which generates a Regular Expression automatically. Once the regular expression is ready, follow below steps for reformatting the date field.
- Choose data field “Date” to reformat
- Click the “Customize Field”
- Choose “Re-format extracted data”
- Click “Add step”
- Select “Match with Regular Expression”
- Input the Regular Expression field with “(?<=Published)(.+?)(?=by) to fetch only the month and year
- Click “Calculate” to check if the result is right
- Click “Ok” to save the result
- Click “Save”
Now the Date is formatted and has only the month and the year pattern. We can refine the scraped fields by applying regex to fit well to our requirements. Repeat the above steps to get the ‘Published’ value in the Status field. Follow the steps 1-5 and input the regular expression as “(.+?)(?= )” to get the Published value in the Status field.
Step 5– Check the workflow. Now we need to check the workflow by clicking actions from the beginning of the workflow to make sure that we can scrape all the data. Below should be the workflow.
The Loop Item box ➜ Go to Web Page ➜ The Loop Item box ➜ Click Item ➜ Extract Data
Finally, Click “Save” to save the configuration.
Section 2 – Local Extraction
Local Extraction is the option to run the task on your computer. A task in Octoparse contains one web scraping rule, and a rule is stored in one OTD file. Once the configuration is saved, the Octoparse rule is saved as OTD file extension. Below are the steps for Local Extraction
After selecting the Extractions Options click “Next” ➜ Click “Local Extraction” to run the task on your computer. Octoparse will automatically extract all the data selected.
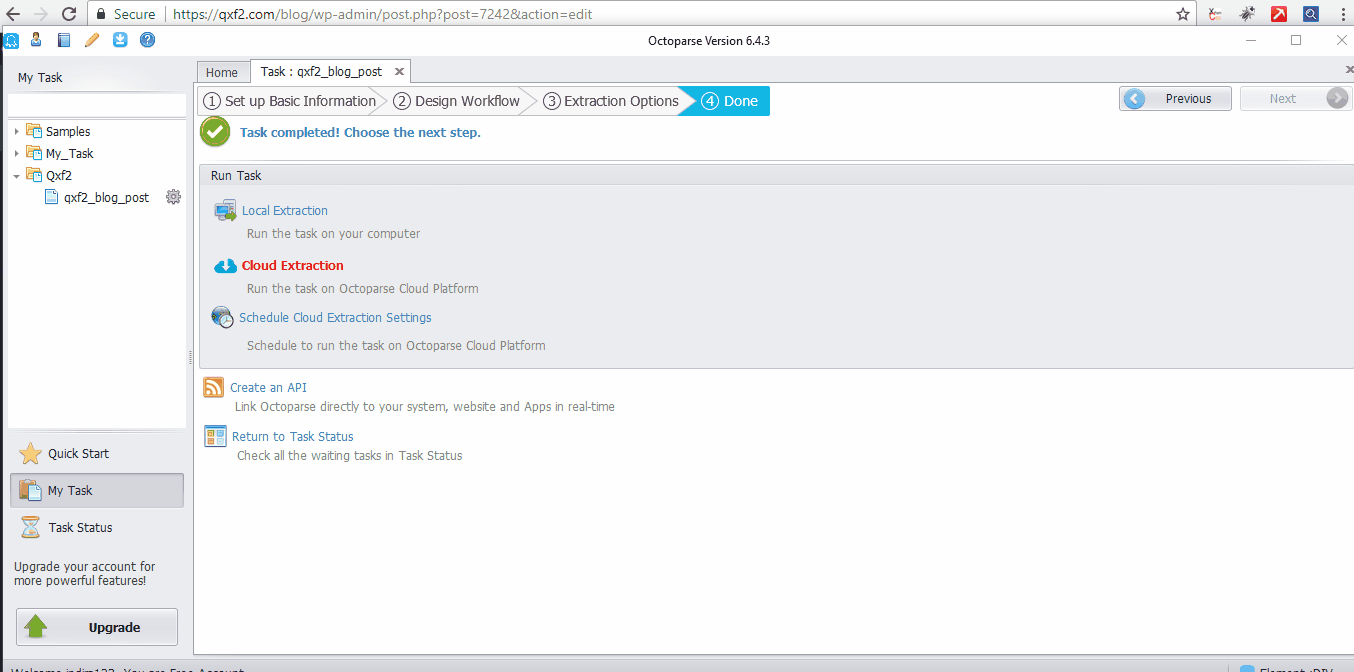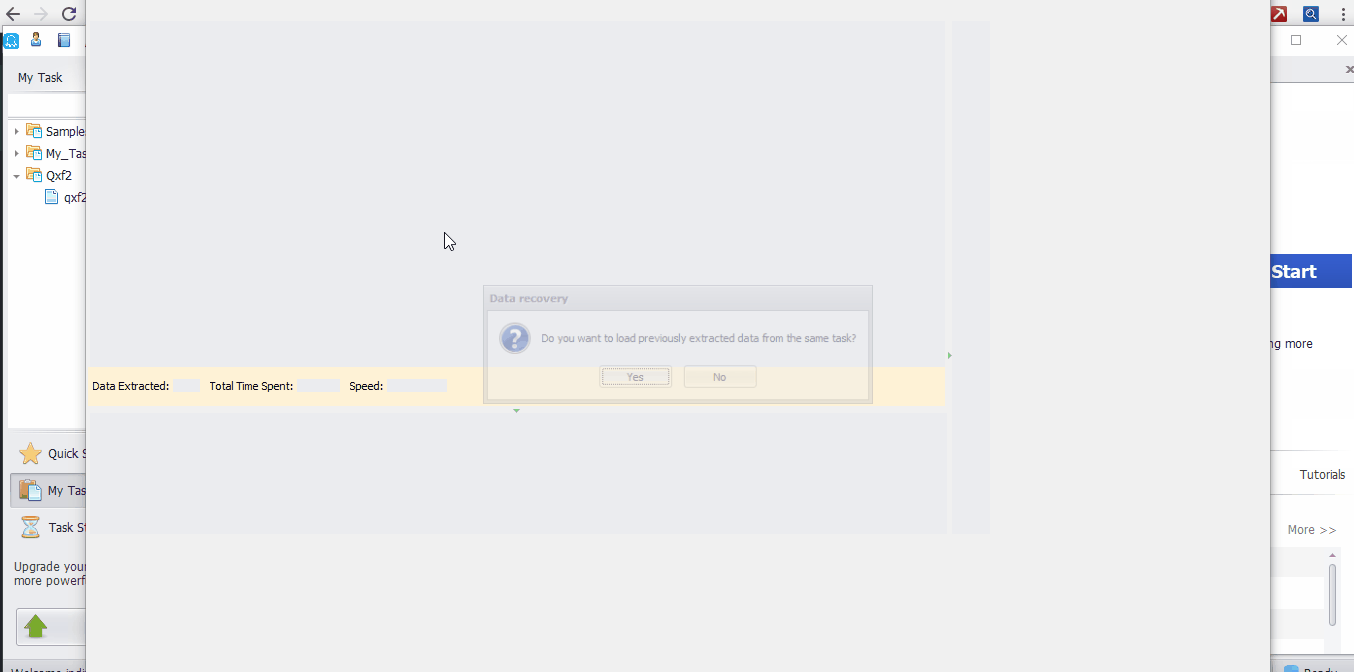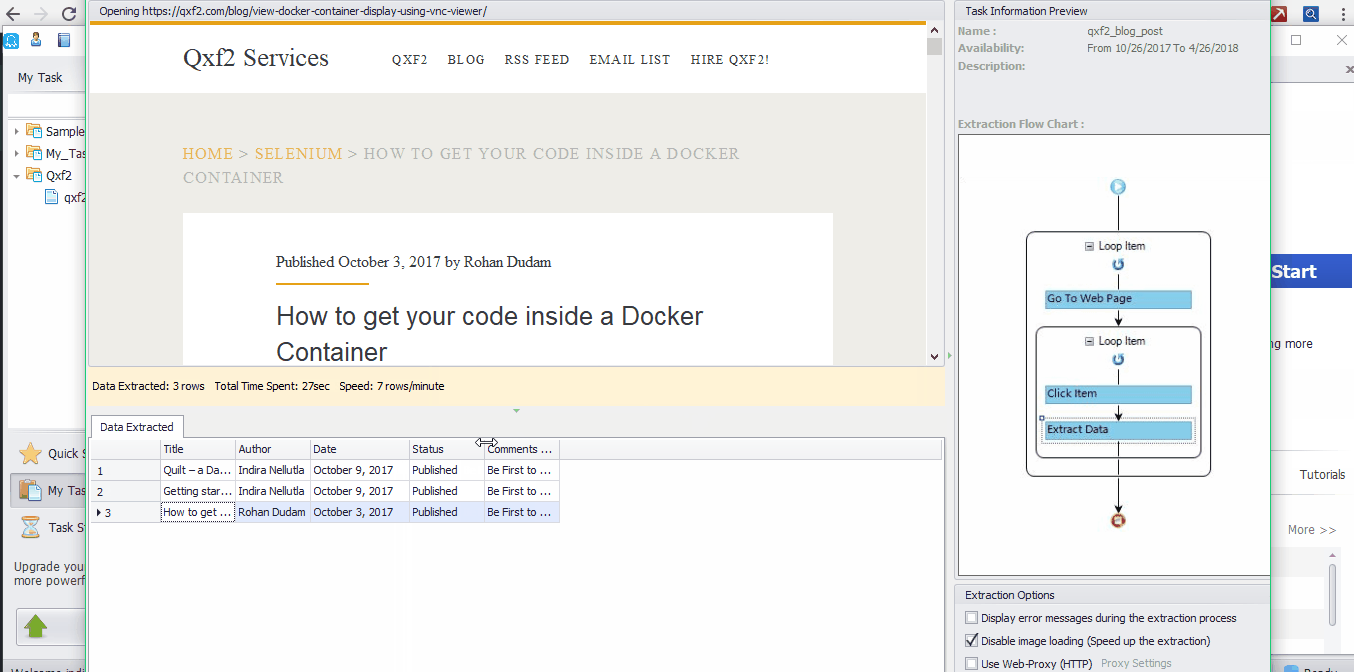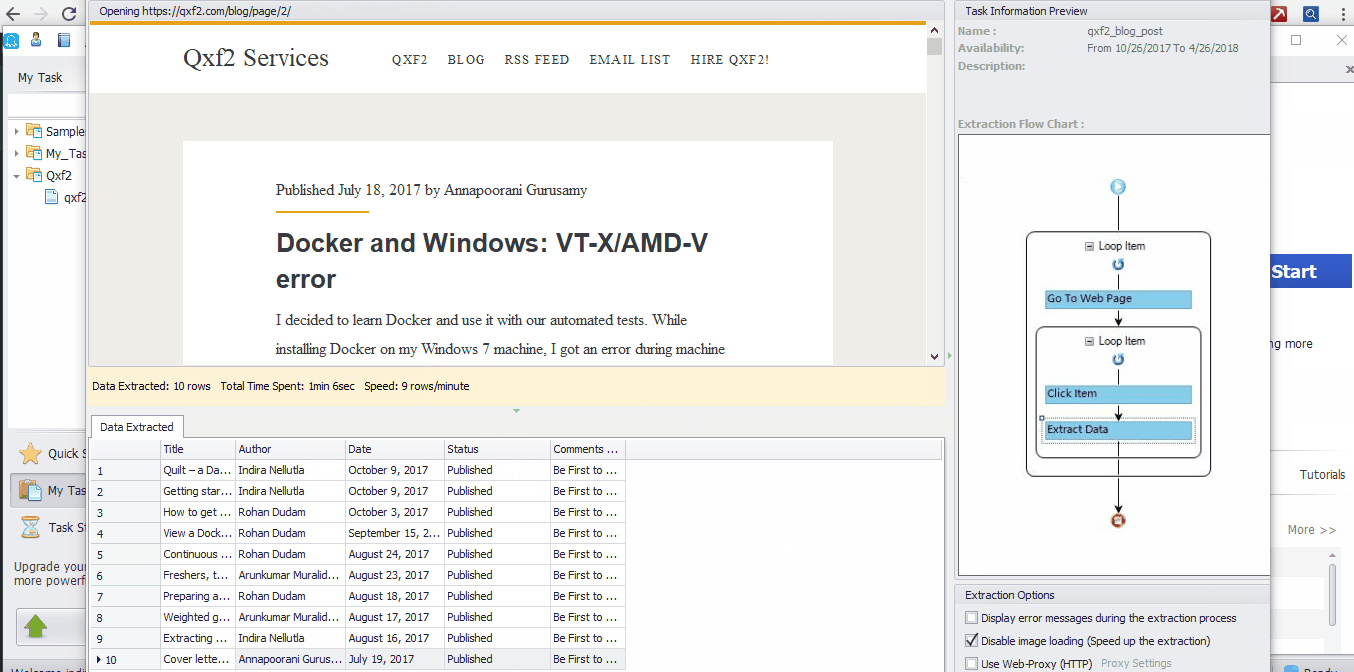
The data extracted will be shown in “Data Extracted” pane. Click “Export” button to export the results to Excel file, databases or other formats and save the file to your computer. We have exported our data into a .xlsx file. You can download the extracted file from here
In this way, we could extract information from our WordPress blog in the format that we needed without writing any code. Octoparse is capable of handling the scraping of most dynamic sites in rather straight-forward ways. It is engineered for most data requirements and the free plan supporting unlimited web page scraping added value. Happy Data Scraping!
If you are a startup finding it hard to hire technical QA engineers, learn more about Qxf2 Services.
References
1) Configuration Rule in Octoparse
2) Use Regular Expression to Reformat Captured Data
3) How to Scrape WordPress Posts
4) Web Scraping Case Study | Scraping Data from Yelp

I am an experienced engineer who has worked with top IT firms in India, gaining valuable expertise in software development and testing. My journey in QA began at Dell, where I focused on the manufacturing domain. This experience provided me with a strong foundation in quality assurance practices and processes.
I joined Qxf2 in 2016, where I continued to refine my skills, enhancing my proficiency in Python. I also expanded my skill set to include JavaScript, gaining hands-on experience and even build frameworks from scratch using TestCafe. Throughout my journey at Qxf2, I have had the opportunity to work on diverse technologies and platforms which includes working on powerful data validation framework like Great Expectations, AI tools like Whisper AI, and developed expertise in various web scraping techniques. I recently started exploring Rust. I enjoy working with variety of tools and sharing my experiences through blogging.
My interests are vegetable gardening using organic methods, listening to music and reading books.


I’ve developed a scraping tool called ScrapeStorm(www.scrapestorm.com), I think it is much easier than this one. I use AI to automate scraping , no programming and even no configuration. Only thing you have to do is entering a list page url like https://qxf2.com/blog/
boom! it will do everything for you:extract the page with several fields, find the next page button, you just need to click start.
hope you guys like it, if you have any questions or suggestions, you can contact me through [email protected]
Hi Tom,
This sounds interesting. We have added it to our R&D backlog and would definitely want to try this software. Thank you for letting us know!