We have been testing data-rich applications for a long time. And like any experienced tester, we realize how difficult it is to create, maintain and update data every time the data model changes. So we were excited to come across Quilt, a data package manager, via Hacker News. We were thrilled that it integrated well with our favorite programming language – Python. So we set about exploring Quilt to see if it could be ‘GitHub for data’. In this post, we will talk about basic operations that we performed on data and how we could access the older data versions using Quilt. We will write a follow up soon with a step by step guide on how to integrate Quilt with your test data.
Note: Quilt talks about storing binary data and therefore not duplicating too much data. As testers, we don’t (yet) care too much about this cool feature. But we are sure if you are a developer or data analyst you will care about this feature.
The need for data versioning
We like creating our own data for testing data-heavy applications. This presents a few problems
1. It is hard to maintain test data when the underlying data model changes. Over time, in any data-rich application, the data model undergoes changes. For example, new fields are added, existing fields get deleted, split or combined. All this means that the test data needs to evolve. We end up writing separate scripts to create data and then to maintain the data.
2 It is very difficult to intelligently name files. As a tester, our instinct is not to design and use databases for our data. Instead, we try to rely on flat files. So if you are like us, you end up a few dozen (or hundred) files named intelligently. To us, this approach has always felt like the poor man’s version control.
Data versioning can solve both these problems. In many cases, simply using git (or your version control tool) is not an option when you have large amounts of data. So we are glad to find version control that is specifically designed for data.
What we especially liked about Quilt, was that it integrates so well with Python. Quilt uses Python pandas’ DataFrame as the default data structure. This makes reading and (especially) editing data so easy! If you have ever tried editing specific columns of a large csv (yeah, we know about fileinput) you will know why we are so happy.
Quilt
Quilt is a data package manager which is a versioned bundle of serialized data wrapped in a Python module. Phew! That was a mouthful! We are new to Quilt, so our understanding may be wrong. But here is our mental model for Quilt. Quilt takes your data and:
a) converts it into a special format (serialized binary)
b) magically transforms your data into a Python module (wrapped in a Python module)
c) lets you commit/store the data in a version control system (versioned)
Once you run your dataset (or a portion of your dataset) through Quilt, you get what is called a ‘data package’. A data package is an abstraction that encapsulates and automates data preparation. By packaging the dataset, you can easily reuse it and manage the different versions. Quilt comes with a command-line utility that builds, pushes, and installs data packages. In this post, we will be covering below areas and show different operations which we have tried using Quilt.
- Use an existing Quilt package
- Create a new Quilt packages
- Managing versions of data
- Edit package contents
1. Use an existing Quilt package
We can either install the already existing published packages from the Quilt website or we can create a new dataset based on the testing requirement and make it public. Firstly, let us understand how to use the existing package.
Quilt Installation – Quilt can be installed with pip using command
pip install quilt |
Package list – Already existing published packages reside here.
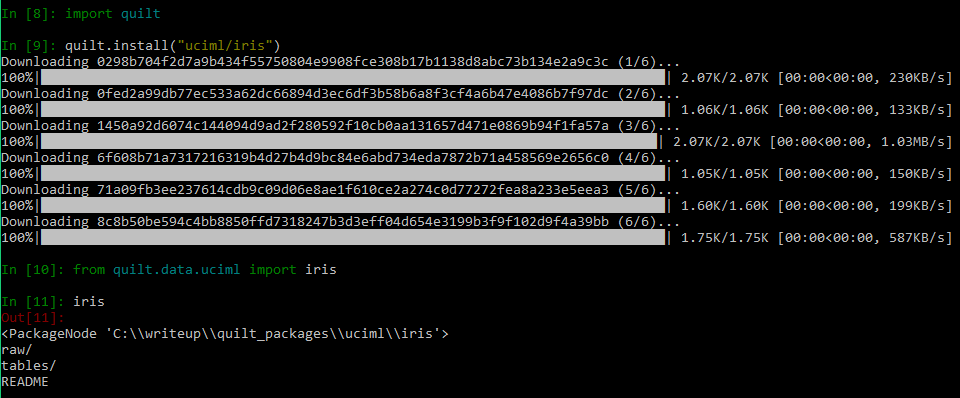
Dataset Installation – Every Quilt command is available both on the command line and in Python. So installing and downloading a data package is very simple. For eg., for downloading a data package for iris dataset from uciml user, we can use below command
import quilt quilt.install("uciml/iris") |
Packages are installed in the current directory in folder named quilt_packages. Now we can load the data directly into Python using import command. You can import the package just like any other python package. You can edit package contents using the Pandas to edit existing dataframe. Below figure shows how to install and import existing quilt packages.
Packages contain three types of nodes:
- PackageNode – the root of the package tree
- GroupNode – like a folder; may contain one or more GroupNode or DataNode objects
- DataNode – a leaf node in the package; contains actual data
2. Create a new Quilt package
For this post, we have created a simple dataset. So we will see how to convert a data file into a data package using a configuration file, conventionally called build.yml. The build.yml file tells Quilt how to structure a package. quilt generate automatically creates a build file that mirrors the contents of any directory.
quilt generate sourcedata |
contents:
README:
file: README.md
quilt_sample_package:
file: quilt_sample.csv |
In the build.yml, the quilt_sample_package is the package name that package users will type to access the data extracted from the CSV file. You can any time edit build.yml to make the data name or package name easier to understand. Each Quilt package has a unique handle of the form USER_NAME/PACKAGE_NAME. Package life cycle consists of core commands like build, push, log, install. To use a data package you import it.
The command quilt build creates a package. Quilt uses pandas to parse tabular file formats (xls, csv, tsv, etc.) into dataframes and pyarrow to serialize data frames to Parquet format. Below is the command for using quilt build
quilt build indira/quilt_sample_package sourcedata/build.yml |

The command quilt push stores a package in a server-side registry for anyone who needs it. You need to be a registered user of Quilt (free tier available) to be able to push and store the package.
quilt login quilt push --public indira/quilt_sample_package |

The package now resides in the registry and has a landing page populated by sourcedata/README.md. Here is the link to the landing page that is created for this package. You can omit the –public flag to create private packages.
3. Managing versions of data
The command quilt log tracks changes over time. Whenever a user changes the data for a particular requirement, the changes are tracked in the log history as shown below. Build and Push commands need to be executed for any data changes.

Finally, the command quilt install -x allows us to install historical snapshots. In our case, we wanted an older version of data, so using quilt install we could retrieve the older version data as shown below
quilt install -x OLD_HASH |

We observed a couple of things here, when we did a quilt install using the OLD HASH tag, we saw a message saying that ‘Fragment already installed; skipping.’ We noticed that the changes made to the data are not reflected. This “skipping” message means that one or more data fragments haven’t changed. The version will still be correct and still gets installed. Currently, Quilt doesn’t delete any no-longer-used data. So, when we build the first version of the .csv, Quilt generates a package. Then we build the second version, but the data from the first version is still around (think of it as a cache). That is why, when we “quilt install” a different version, it says that we already have the data. Any changes made to the data are actually seen only when we actually import the package. When you see different fragment hashes when you install different versions, it confirms that the data is different. When you run “quilt install“, you should see something like this:

When we try to install a different version, we should see a different hash in the “Downloading” message. (If you don’t, then something is in fact wrong.).
4. Edit package contents
Data packages are like folders containing dataframes. So we can use Pandas API to edit the dataframes. With Python’s dot operator you can traverse a data package as shown below.
from quilt.data.indira import quilt_sample_package df = quilt_sample_package._data() print (df) |
The _data() method caches the dataframe so it will return the same object each time. We can use set_value command to set the values to the data and make changes to the data as shown below
df.set_value(0, 'radius', 15) |
In the above code, we modified a value in the ‘radius’ column. Similarly, we can use _set method on the top-level package node to create new groups and data nodes as shown below.
# Add a new dataframe df = pd.DataFrame(dict(a=[1, 2, 3])) quilt_sample_package._set(['test', 'df'], df) # Add a new group quilt_sample_package._add_group("testgroup") quilt_sample_package._set(['test', 'testgroup', 'df'], df) |
Once the changes are made to the data, at this point the package owner need to build and push to update the package and verify the new contents.
quilt.build("indira/quilt_sample_package",quilt_sample_package) quilt.push("indira/quilt_sample_package") |
We will follow this post up with one more post with step by step guide and a hands-on example on how to use Quilt. Stay tuned!
If you are a startup finding it hard to hire technical QA engineers, learn more about Qxf2 Services.
References
1. Introduction to Quilt
2. Data-packages-for-fast-reproducible-python-analysis
3. Manage-data-like-source-code

I am an experienced engineer who has worked with top IT firms in India, gaining valuable expertise in software development and testing. My journey in QA began at Dell, where I focused on the manufacturing domain. This experience provided me with a strong foundation in quality assurance practices and processes.
I joined Qxf2 in 2016, where I continued to refine my skills, enhancing my proficiency in Python. I also expanded my skill set to include JavaScript, gaining hands-on experience and even build frameworks from scratch using TestCafe. Throughout my journey at Qxf2, I have had the opportunity to work on diverse technologies and platforms which includes working on powerful data validation framework like Great Expectations, AI tools like Whisper AI, and developed expertise in various web scraping techniques. I recently started exploring Rust. I enjoy working with variety of tools and sharing my experiences through blogging.
My interests are vegetable gardening using organic methods, listening to music and reading books.


Hi, I don’t think Quilt stores all versions of the files. Rather all new file versions overwrite older version files. From what I read on their FAQ page [1] and my test scripts, the older versions of the files are not recovered.
[1] https://docs.quiltdata.com/more/faq
Correction: actually if you enable S3 bucket versioning and clear all Quilt cache, Quilt does download correct file versions. But without S3 bucket versioning On and without clearing the cache Quilt will not show any warning and will just download incorrect (lastest) versions. Sorry for confusion.