I want to share my experience of using Dask tasks and certain best practices/optimizations I implemented. Having some prior understanding about Dask is required to follow along. For implementing parallelism, I used Dask futures, one of the Dask collections. I referred Dask best practices on how to improve performance and incorporated some of them to my project. Hope you find some of these useful as well!
What’s the context?
I worked on a Python project to explore parallelism using Dask while running it on a Coiled Cluster. The project creates control heatmaps for chess games. Control heatmap graphically shows us how much control White/Black has on each square on the chess board. This is for every ply (half a move) in the game. The input can take any number of games in PGN format. I designed two levels of parallelism – one where all the games that are taken as input are run in parallel. And the second one was to calculate the power of each square for each ply in parallel. So, different workers pick different games and each worker in turn submits tasks to scheduler for square power calculation. Consider, for instance, 10 games each having 10 plies. Each ply has 64 squares and to calculate the power of each square for White and Black would require 128 tasks. So, for 10 plies the number of tasks will be 1280 and for all games in a single run, 12800. Which worked great even on a local client.
Where was the problem?
I tested for 1000 games and was caught off-guard when I saw it failing all over the place. The client was getting timed out, workers killed and games left midway. To get things in control, I first tried to modify the configuration. Added more workers to coiled (16 from 8), increased CPUs and memory (4 CPUs and 30GB from 1 CPU and 8GB), expanded Scheduler CPUs and memory (4 CPUs and 30GB from 1 CPU and 8 GB). With this I noticed slight improvement, but still the test didn’t go through and kept timing out a few mins after it started. I now started suspecting if the problem is with the scheduler. Looking at the Dask dashboard (via Coiled) when the test started, I observed that CPU usage of the scheduler goes to 100% just after a few seconds of the test start and doesn’t come down.
Tip 1: Batch tasks if your scheduler is overloaded
Batch the tasks to avoid overloading the scheduler. For 1000 games there were millions of tasks created and to handle these better, makes sense to send few of them each time instead of all at once. I started with 30 games in a batch with 16 workers. There was a lot of improvement and progress! But the issue was not completely resolved. I saw that the first level game task – which creates the sub tasks per ply per square is stuck for a long time and eventually, all the workers are stuck with the same first level tasks. I realized that because these tasks create sub tasks and wait for them to complete and do not release the worker until they complete, they are stuck because there are no workers who can take up the sub tasks (this is a deadlock). So I tried with batch size of 10 games still saw that the scheduler CPU becomes 100%.
batch = [] for game in game_master_list: batch.append(game) if index % self.config_values["game_batch_size"] == 0: [more code] |
Tip 2: Group short tasks as a single task
If the task is too short, lesser than 100ms, then its best to group some of the tasks as a single task. Scheduler spends more time scheduling the tasks than actually getting a worker run those tasks. I validated this in my run by checking the worker CPU, which was always 2-5% while the scheduler CPU was always 100%. Now I decided to change the logic to add fewer, longer running tasks than adding lot of short running tasks. So now the sub tasks are per ply and not per ply per square. So for our example, the tasks have become 100 (10 games X 10 plies). And for 1000 games, the number of tasks have considerably reduced. The test progressed a lot but was still slow.
for square in SQUARE_NAMES: parsed_square = parse_square(square) power_of_square_dict = {"ply": ply_no} power_of_square_dict['square'] = parsed_square |
Tip 3: Make use of client.map for large number of tasks
When there are large number of tasks, use client.map() and client.gather() for submitting and collecting the tasks respectively. I had initially used client.submit() and future.result(). After implementing this found the test running smooth without any games getting timed out. Next, I added more optimization – increased the workers count to 50, each with 1 CPU and 8GB RAM and game batch size to 30. With this, the analysis part got completed in 2 minutes which is quite fast!
worker_client = get_client() task_futures = worker_client.map(ChessUtil.find_control_for_square, tasks_for_game["game_tasks"]) |
Tip 4: Try more workers with single CPU
All dask workers are by default started as daemonic processes, because of which it is not possible to use the python multithreading in the tasks running inside the workers. So instead of creating a worker with more number of CPUs, I created more workers with a single CPU and passed on all the tasks that can be parallelized to the scheduler. Earlier, I was using 16 workers with 4 CPUs each, and changed this config to use 50 workers with 1 CPU each which worked out well for me as more tasks can be done in parallel.
Tip 5: For concurrent processing use as_completed
Use as_completed to simultaneously process any dependent tasks(on the primary ones). This method from dask distributed library blocks until a task gets completed and returns the result where as client.gather() blocks until all the tasks get completed.
image_futures = self.client.map(ChessImageGenerator.create_gif, all_game_results) for image_future in as_completed(image_futures): image_data = image_future.result() |
Here are snapshots of the Scheduler CPU usage before and after the optimizations:
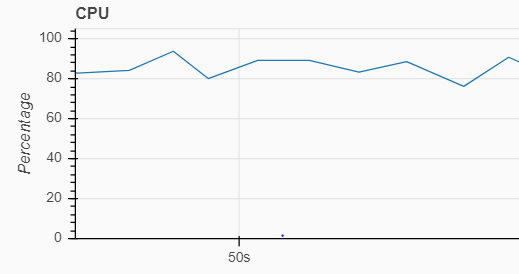

With all these optimizations, the total time taken to run the test was around 20 mins -2 minutes to process the games and the rest for the heatmap gif creation (am yet to optimize this part further).
If you are interested to check out the project, it is here – https://github.com/qxf2/chess-heatmap. And the related blog is here – Visualize chess heatmap using dask and coiled Do share your thoughts in the comments.
I have been in the IT industry from 9 years. I worked as a curriculum validation engineer at Oracle for the past 5 years validating various courses on products developed by them. Before Oracle, I worked at TCS as a Manual tester. I like testing – its diverse, challenging, and satisfying in the sense that we can help improve the quality of software and provide better user experience. I also wanted to try my hand at writing and got an opportunity at Qxf2 as a Content Writer before transitioning to a full time QA Engineer role. I love doing DIY crafts, reading books and spending time with my daughter.


Hi Sravanti,
I’ve been having trouble managing large (million+ tasks) dask jobs for a couple years now and this write-up helped me to finally figure out how to fix it. I especially appreciated your suggestions on batching up the jobs & using client.map. Those worked wonders at speeding up my computations. Thanks for the write-up!
Hi Brendan,
Thank you for your kind feedback on my blog post! I’m glad to hear that the suggestions were beneficial and helped speed up things for you. This means a lot to me!