I recently implemented a Python script to trigger AWS Lambdas conditionally as part of a Microservices app we built at Qxf2 . I experienced multiple invocations of the lambda issue, which made me go in circles. Hence, I decided to share the thinking behind and the fix.
Spoiler: The culprit happened to be a default timeout setting in the boto3 client. You can control this by changing the boto3 client’s config.
Background:
Three AWS Lambdas needed to be executed in a pipeline as part of our Microservices app. Something like this:
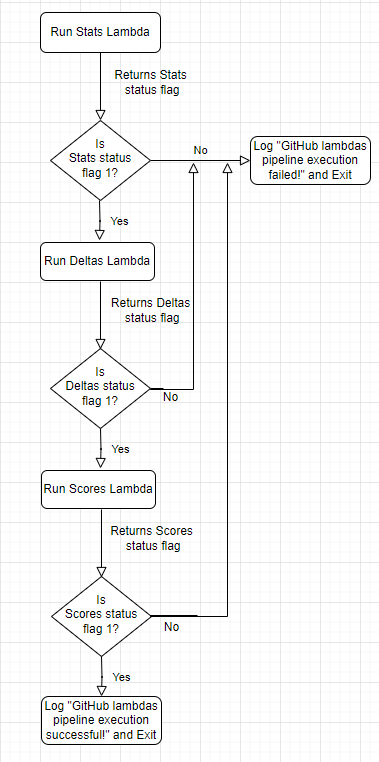
The pipeline above utilizes the first lambda to fetch Qxf2’s Public GitHub repositories statistics for certain metrics, the second lambda to calculate the deltas for these statistics, and the last lambda to calculate the scores based on certain aspects and write data into DynamoDB tables at every step.
AWS SDK for Python (Boto3) was used to create client objects and invoke the lambdas synchronously using the RequestResponse invocation type. The flowchart above demonstrates the conditional triggering of the lambdas. This logic was tested on my machine using localstack and awslocal, and the AWS lambdas conditional trigger Python script was then deployed to a production EC2 instance, scheduled to run every night by setting up a cron job.
Issue:
The production runs revealed that the first lambda in the pipeline was invoked multiple times instead of just once. On a bad day, these multiple invocations resulted in an AWS Lambda ReadTimeOut Error, causing data fetch and storage issues, leading to a cascading effect. The Great Expectations tests designed to verify the quality of the GitHub stats, deltas, and scores data also failed, necessitating immediate issue resolution and root cause analysis.
Spoiler:
If you are not interested in knowing the thinking behind, you could directly find my AWS lambdas conditional trigger Python script with the fix here: AWS lambdas conditional trigger script
Investigation:
I had to reproduce the multiple invocations issue. I ran the script on my machine and it worked perfectly. Now I had to test it in production to verify the actual runtime behavior. As I mentioned earlier, there were three lambdas in the pipeline to be executed one after another, based on the successful execution of the previous one. However, we observed the multiple invocation issue only in the stats lambda (the first one). So I tweaked the stats lambda return flag’s comparison value in the AWS lambda’s conditional trigger script to ensure only the stats lambda was invoked in isolation. I also commented out the stats lambda code to make it just return the status rather than reading GitHub stats or writing into storage.
PS: I ensured to reset the changes made, once the testing was completed, as it was production code expected to be run every night.
Tools used for verification at this point:
AWS CloudWatch Logs, AWS CloudWatch invocations metrics and custom logs of the AWS lambdas conditional trigger script.
Test scenarios and observations:
(*) When stats lambda was triggered using the test event on AWS lambda console: (PS: Test Event invocations are asynchronous).
Observation : Run successful. Only one invocation was found in CloudWatch logs and script’s custom logs
(*) When stats lambda was invoked using the AWS lambdas conditional trigger script (Synchronous invocation) on my machine.
Observation : Run successful. Only one invocation was found in CloudWatch logs and script’s custom logs
This confirmed that the multiple invocation of the lambda issue was not related to the invocation mechanism used in the code.
(*) The lambda’s asynchronous invocation configuration on the AWS console, had the default retries set to 2 . But I was synchronously invoking the lambda as part of AWS lambdas conditional trigger code. Hence this wouldn’t apply.
(*) The synchronous invocation code was not within a loop in the AWS lambdas conditional trigger script.
(*) Exceptions were handled in the AWS lambdas conditional trigger script and logged.
(*) Did not find any errors in the AWS Lambda’s CloudWatch logs. Each of the multiple invocations had been a successful, clean run.
Except for that one bad day when a AWS Lambda ReadTimeOut error was observed in the cron logs.
From the above thinking, there was no specific pattern that I could infer. Some days the stats lambda was invoked just once as expected. On other days twice, with a maximum of thrice.
Digging into the ReadTimeOut Error:
I had redirected the Standard Output and Standard Error of AWS lambdas conditional trigger script’s cron job to a custom log.
00 00 * * * ~project/venv_lambdas_39/bin/python3 ~/project/invoke_lambdas_conditionally.py >> ~/project/log/invoke_lambdas_conditionally_cron.log 2>&1 |
Went about digging into the invoke_lambdas_conditionally_cron.log custom log. On that bad day, three invocations of stats lambda were observed, one after another, each lasting for about a minute. Confirmed using CloudWatch logs and invocations metrics view of the lambda on AWS console.
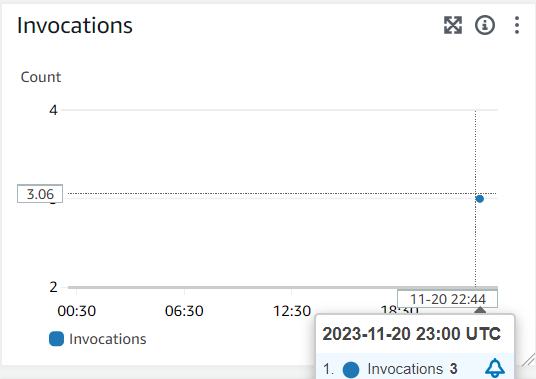
All three invocations were successful and hence stats data was overwritten into DynamoDB table. Each invocation was a request with only one successful attempt. No retries were done as expected. Hence there was no point investigating the retry policy.
However, ReadTimeoutError – botocore Exception was raised and entry was found in the invoke_lambdas_conditionally_cron.log custom log. The boto3 client had timed out. Hence deltas and scores lambdas had not been triggered though the stats lambda run was successful. This had resulted in Great Expectations checks failing for the day, owing to no data in deltas and scores.
Timeout setting of stats lambda (i.e. How long can one invocation run to a max) was set to 3 minutes (default being 5 minutes) in the AWS console’s lambda configuration. However , in the AWS lambdas conditional trigger script, boto3 client was created with default setting.
client = boto3.client('lambda') |
On an average, the stats lambda’s runtime was observed to be ~70 secs (to fetch stats for 60+ public repositories. Repository count is only expected to increase with time). Even though the lambda function’s timeout was set to 3 minutes, the boto3 client’s read timeout defaults to 60 seconds. Each time it reached this client timeout of 60 seconds, it must have triggered a retry. Also, boto3 client’s default retry is 3 attempts.
So these observations clearly pointed me to the root cause of the issue, which was read_timeout configuration of boto3 client.
Fix:
Updated the boto3 client’s read_timeout by referring to Boto3 Config Reference, from default of 60 seconds to 120 seconds. This fixed the multiple invocation issue.
boto3_config = Config(read_timeout = 120) client = boto3.client('lambda', config = boto3_config) |
Testing the fix:
Had tested the fix by,
(*) modifying the read-timeout config to 5 seconds and it resulted in multiple invocations of the stats lambda.
(*) modifying the read-timeout config to 120 seconds and it resulted in only one invocation of the stats lambda as expected.
Had decided on 120 seconds for now, to accommodate fetching stats for Qxf2’s growing public repos. Might have to revisit based on Qxf2’s GitHub repo count increase. Fix was deployed to production and observed a clean run the following day.
Also had moved the AWS lambdas conditional trigger script into an Airflow DAG as we prefer keeping our data pipelines orchestrated in Airflow at Qxf2. Had used Airflow’s TaskFlow API to implement data communication between the various tasks.
Finally, what I had assumed to be a bad day when I found the multiple invocations issue in the lambda, ended up being an interesting, learning day! Hope you found this post useful! Happy building and testing!
Hire Quality Engineers from Qxf2
Qxf2 employs technical testers with a wide range of testing expertise. Like in the article above, our testers are capable of analyzing systems, understanding code and debugging complex issues. Engineering teams love working with us. Our initiative and technical abilities make it easy for developers to collaborate with us. If you are looking for good QE to augment your team, get in touch with us.
I have done my Masters in Software Engineering. I am very passionate about testing and I’ve had the opportunity to work in different phases of the software life cycle. Have built and tested various applications. My curiosity drives me to explore, learn and keep myself updated. Qxf2 keeps me constantly challenged with interesting work and encourages me into blogging about it. I love music, reading and staying fit!

