In our previous post, we suggested that Accessibility ID as a reliable locator strategy for identifying mobile elements across different platforms. While working on the task, we explored another plugin – Appium OCR Plugin that helped us write robust XPaths to validate UI that worked on both iOS and Android. But the problem we had was, although we were able to use this plugin in our local setup, remote test execution platforms have not yet supported it. We’re writing this post to share our findings with the testing community, especially those who could benefit from using this plugin.
Why OCR?
We had an existing automation test that validated an error message that appeared when the user entered invalid payment details. Initially, we used the Tesseract OCR Python library to verify the presence of this message. However, including Tesseract in our requirements.txt just for this single scenario felt like overkill, it unnecessarily bloated our test environment. While exploring alternatives, we came across the Appium OCR plugin, which allowed us to validate the error message effectively. As we dug deeper into how the it works, we realised it could also serve as a viable option for identifying UI elements across mobile platforms.
How does the OCR plugin work?
When we start the Appium server with the --use-plugins=ocr CLI option, it adds an additional context—OCR to the mobile app session and updates the page source corresponding to text objects found on the screen.
The image below shows a side-by-side comparison: the NATIVE_APP context on the left and the OCR context on the right.
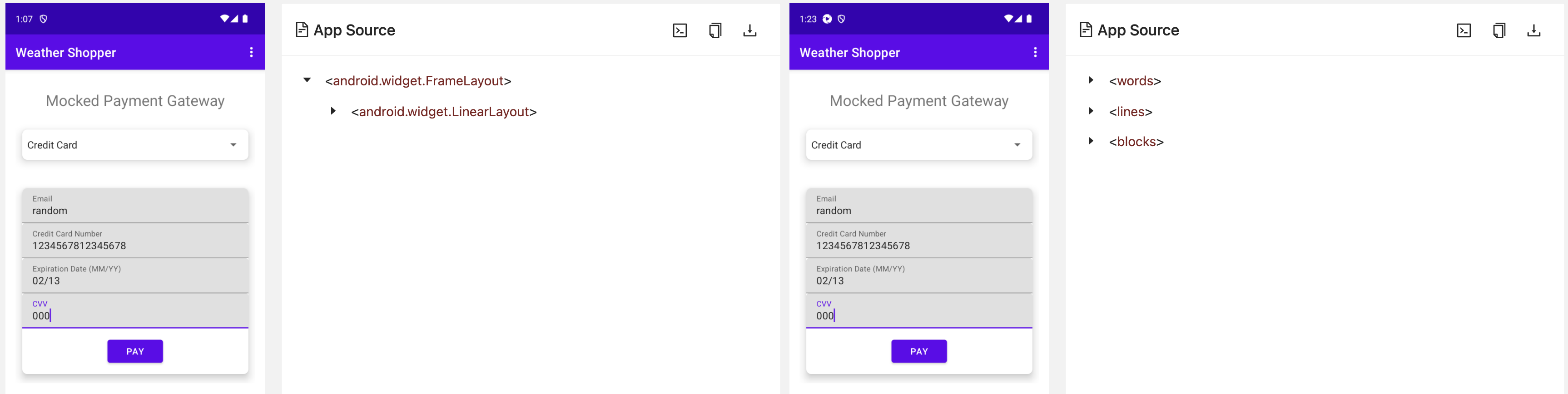
In the NATIVE_APP context, the page source shows the UI hierarchy, a tree structure representing how UI elements are arranged and nested. In contrast, the OCR context provides an XML structure generated by the OCR plugin, where elements are represented purely by their visible text.
When we switch to the OCR context, the plugin dynamically generates and updates the app source with OCR-based XML like this:

This text-based representation made us wonder: could we use it to uniquely identify elements on the screen? We experimented by writing XPaths using the text() function to locate elements in the OCR-derived source. It worked. We successfully replaced our earlier Tesseract-based validation with this OCR plugin. The process was straightforward: We crafted an XPath for the error message text and verified the element’s presence within the OCR context.
Setup
Here’s how you can install the Appium OCR plugin:
appium plugin install --source=npm appium-ocr-plugin |
To use the plugin, start the Appium server with:
appium server --use-plugins=ocr |
When you launch the server with the plugin enabled, it adds a new OCR context to your app session. You can then switch to this context to write robust, text-based XPaths with ease.
Writing an XPath to identify element
We currently use pytesseract to extract text from images. Here’s how we do it:
image_dir = self.screenshot_dir full_image_path = os.path.join(image_dir, f"{image_name}.png") # Check if the file exists if os.path.exists(full_image_path): # Load the image image = Image.open(full_image_path) # Enhance the image before OCR enhanced_image = self.preprocess_image(image) # Perform OCR on the enhanced image text = pytesseract.image_to_string(enhanced_image) else: text = "" return text |
Although our current approach worked, using a Python module added unnecessary size and complexity to everyone’s test setup. The Appium OCR plugin offered a cleaner alternative, letting us run validations only when needed. This kept our overall test setup lightweight and efficient.
With OCR enabled on the Appium server, checking for text like Invalid email address became straightforward using a simple XPath:
driver.switch_to.context("OCR") invalid_email_message = driver.find_element(AppiumBy.XPATH,f"//lines/item[text()='Invalid email address']") if invalid_email_message.is_displayed(): print("Successfully validated that the error message is displayed") else: print("The error message is not present") |
The OCR context simplifies error message validation by giving direct access to the visible text on screen. By using the text() function in XPath queries, we can reliably locate and verify content across platforms in mobile automation tests.
Note: The code examples in this post are simplified and contrived versions of what we use in our actual test suites. They are intended for illustration purposes only and do not reflect our production coding standards or best practices.
OCR Simplifies Testing, But the Ecosystem Isn’t Ready
While this new plugin initially got us excited, our enthusiasm quickly faded. When we ran the same setup on BrowserStack, we hit a roadblock – BrowserStack and other remote test execution platforms don’t currently support the OCR plugin. As a result, we can use this capability only in our local test environment.
So there you have it, a powerful yet underrated plugin that helps you write robust, text-based XPaths for cross-platform mobile apps. By tapping into OCR-generated page sources, the plugin simplifies content validation and element identification across both iOS and Android. The only catch? For now, platforms support it only during local test runs. Still, it’s a great addition to your local automation toolkit and one worth watching as broader platform support develops.
Essential Service offering from Qxf2
Qxf2’s Essential Service offers front-loaded QA support tailored for startups, combining exploratory testing, automated test suites, and CI integration to streamline release testing. This cost-effective solution provides expert QA without the need for a full-time hire, ensuring efficient and reliable product releases. Reach out to [email protected] to learn more.
My expertise lies in engineering high-quality software. I began my career as a manual tester at Cognizant Technology Solutions, where I worked on a healthcare project. However, due to personal reasons, I eventually left CTS and tried my hand at freelancing as a trainer. During this time, I mentored aspiring engineers on employability skills. As a hobby, I enjoyed exploring various applications and always sought out testing jobs that offered a good balance of exploratory, scripted, and automated testing.
In 2015, I joined Qxf2 and was introduced to Python, my first programming language. Over the years, I have also had the opportunity to learn other languages like JavaScript and Shell scripting (if it can be called a language at all). Despite this exposure, Python remains my favorite language due to its simplicity and the extensive support it offers for libraries.
Lately, I have been exploring machine learning, JavaScript testing frameworks, and mobile automation. I’m focused on gaining hands-on experience in these areas and sharing what I learn to support and contribute to the testing community.
In my free time, I like to watch football (I support Arsenal Football Club), play football myself, and read books.

