In this post, we’ll briefly outline how our Data analytics, Machine learning and AI roadmap looks. We’ll also give you a feel for how work proceeded before we had a roadmap and how it has proceeded after we came up with one.
Note: We ended up doing a lot more in this area since we have some mathematics expertise (for engineers, that is!) in our background.
Why use a roadmap in the first place?
The return on investment on R&D is not obvious. Our R&D work, in the short term, seems to go waste and is largely ignored. On the other hand, employees like to know that they are making progress. They want some validation that the work they do matters. These two conflicting forces makes it hard for us to help employees get started on R&D work. When they start, our employees want to know what exactly they will be accomplishing and why will it matter. We caved in and presented people with an inaccurate plan (a high level roadmap) rather than no plan at all. And surprise, surprise! People had a much easier time getting started with R&D. Once they got started, they ignored the roadmap and generated their own next steps.
Why should a tester even look at this?
Because this is going to be a standard part of your work sometime in the next few years. To learn more, read The need for change (at Qxf2).

The Data analytics, Machine learning and AI roadmap
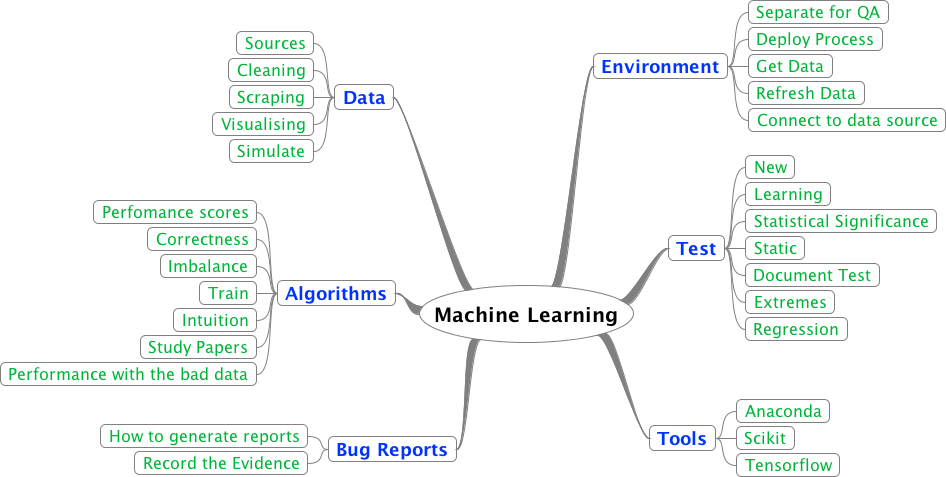
At a high level (blue nodes), here is what we listed:
1. Data: We feel working on scraping and cleaning data is the best entry point for a tester to get involved in the fields of data analytics, machine learning and AI. All algorithms operate on data and the data found in the natural world is messy, unstructured and often incomplete. So learning to generate data, scrape data, clean it up and visualize it nicely is going to be a critical skill for testers.
2. Algorithms: We will need some understanding of how algorithms work. We may not need to know how the mathematics works but developing a feel/intution for how an algorithm performs and how you can measure error is going to be important.
3. Bug reports: Most bugs are not going to be easily reproducible because they depend on the ‘state’ of the system. So we need to figure out good ways to capture and package the state and convey it to the developers.
4. Environment: Maintaining a QA environment is going to be a real challenge. There are some complexities with implementing a ‘clean’ environment to run repeatable tests is going to be hard. The deploy processes look different and you will need to be able to connect to different data stores. So in other words – fun!
5. Existing tests: There are some quick and dirty statistical tests that already exist to measure the performance of many algorithms. It would be good to at least know of them.
6. Tools: We love Python. So we are looking for a Python stack that can help us. We suspect we will have to get used to working with JavaScript charting packages too.
Where we started
We were trying to compare images at one of our clients to figure out if certain tests passed or failed. We were annoyed by something experts call ‘registration errors’ … which is a fancy way of saying the that the two images being compared were not perfectly ‘aligned’ on top of each other. So two images with the same ‘content’ ended up looking different when we did a pixel-by-pixel comparison. We ended up gathering a number of instances that a human would pass and also a bunch of real failures. We used scikit and fed our data to a simple SVM. The code itself was only ~20 lines. Unfortunately, we had to scrap this and not use it long term because we found a much simpler workaround (resize the browsers before taking the screenshot). Not a ceremonious start, but we still felt good about ourselves.

Baby step 1 – Exploring Anaconda
We heard a lot of good things about conda and decided to use it. One of us got setup with it and started using it. We really like Anaconda. We managed to get familiar with the Navigator, create different environments, learnt to shift between the different environments. After that, we got used to pandas, numpy, scipy. We retrieved, merged, stored, edited and visualized data from Quandl. We were in the process of improving our hiring process for junior candidates. So we analyzed some survey data from Aspiring Minds using conda. I think we ended up learning a lot about matplotlib and using dataframes. This phase lasted about 4 weeks for one person.
Baby step 2 – Kaggle Titanic example
We tried the famous Kaggle Titanic example. Based on our previous work, this turned out to be just fine. We noted a number of tools that we wished we had to make our lives easier. We spent extra time here trying to experiment with the Titanic example largely because it was small enough to be a fertile playground for experimenting. We got interested in the accuracy metrics being used to measure the algorithm’s performance. Our interest lead us to our third baby step. This phase lasted about four weeks for one person.
Baby step 3 – Accuracy metrics
We spent a couple of weeks trying to get a feel for the different accuracy metrics involved. We developed simple datasets to see how the accuracy varied in different cases. We did this to develop an intuitive feel for how things changed. If you are curious, try thinking about the shape of the curve ln(f(p)/g(p)) where p is probability of something and f and g are functions. This was a fun exercise. I cannot say we remember too much but performing this work helped us gain confidence.
Work done since the roadmap
Sometime in mid-June, we felt confident enough to get even more technical. We created our roadmap. And we started reading technical papers. We first read the original paper about t-SNE – a very popular (and visual!) dimension reduction technique. We also read a paper about tidy data that helped us get familiar with structuring data better. Since then, we have managed to learn how to scrape tables from PDFs, parse Wikipedia data in multiple ways, use GUI based web scrapers, generate mock data quickly. Of late, we have been exploring several JavaScript based charting packages. We realized the need for versioning data and are exploring Quilt and Pachyderm.
Key takeaway: The roadmap helped us get started. We continue to land at places we would not have imagined. But that is ok. Discovering next steps is what happens naturally over the course of work.
Developing a feel for the work
No one person at Qxf2 can be expected to know everything we are trying to cover. So it is important to develop a ‘feel’ for the progress. We feel much better about this starting point because it seems to have a number of characteristics that overlap with some of our previously successful starting points:
a) The work feels like a multi-purpose move. Learning pandas has made it much easier for us to create and manipulate test data. Also, our DevOps was strengthened in strange ways. To get started with Pachyderm, we needed to figure out Kubernetes and that in turn let us learn more about both minikube and Google’s cloud offering.
b) There are ‘familiar’ elements. We have one foot firmly planted in an area we know well. So we aren’t leaping too far out of our comfort zone. The person doing the work has enough support within Qxf2 and on the Internet.
c) The engineer’s resume gets better. Our engineer, if he/she wishes to quit Qxf2, still has a very strong and relevant skill on their resume
Worth repeating
If you are planning on trying something similar with your team, we’d like to reiterate two things that have helped us:
a) keep the weekly tasks small and specific
b) don’t get too attached to deadlines
Just focus on what is being done and what you can learn from it.
Related posts
- Where is Qxf2 headed?
- The need for change (at Qxf2)
- An introduction to R&D at Qxf2
- An introduction to training at Qxf2
- An introduction to hiring and onboarding at Qxf2
- Experimenting with team structures at Qxf2
I want to find out what conditions produce remarkable software. A few years ago, I chose to work as the first professional tester at a startup. I successfully won credibility for testers and established a world-class team. I have lead the testing for early versions of multiple products. Today, I run Qxf2 Services. Qxf2 provides software testing services for startups. If you are interested in what Qxf2 offers or simply want to talk about testing, you can contact me at: [email protected]. I like testing, math, chess and dogs.

