The importance of data quality in model training cannot be overstated. A high-quality, well-balanced dataset is the foundation upon which effective models are built. Without it, even the most sophisticated algorithms can produce unreliable or biased predictions. Before jumping into testing a model, it is crucial for data scientists and testers alike to have a clear understanding of the data preparation strategies to balance the classes in a dataset to ensure optimal model performance after training.
But testers rarely get any exposure to such techniques, leaving a gap in not only our understanding, but also our ability to articulate the resulting problems coherently. Having noticed this gap, we decided to do the work that a data scientist usually does before training a model, albeit on a smaller and more illustrative problem. We are sharing the same to help you get a feel for the strategies typically employed to enhance a dataset. This post will also enrich your vocabulary enabling you participate in discussions with data scientists and ML engineers alike.
Note: This post builds on our previous work – Data quality matters when building and refining a Classification Model
Why this post?
Recently, we worked on training a BERT model to predict PTO messages in our Skype channel. While we already have a live model for this task, we decided to fine-tune the model using Transformer’s Trainer object to stay updated on the latest techniques and the complexities of model training. Fine-tuning BERT on a relatively small dataset posed unique challenges, requiring us to experiment with various strategies to achieve optimal results. In this post, we’ll walk through the key decisions and insights from our data preparation phase, highlighting what worked, what didn’t, and the lessons we learned along the way
Note: This post will focus specifically on the data preparation and model evaluation steps; the actual fine-tuning (training) process is beyond the scope of our discussion here.
Dataset Preparation
Our dataset was relatively small, containing only around 4,000 univariate data points, which created challenges for achieving strong model generalization. Additionally, the dataset was highly skewed, with one of the two classes significantly underrepresented. This imbalance introduced additional difficulties in ensuring that the model didn’t become biased toward the majority class, emphasizing the need for careful attention during the data preparation phase to ensure the model could effectively learn from both classes.
To better illustrate the class distribution in our dataset, here’s a pie chart showing the composition of each class:
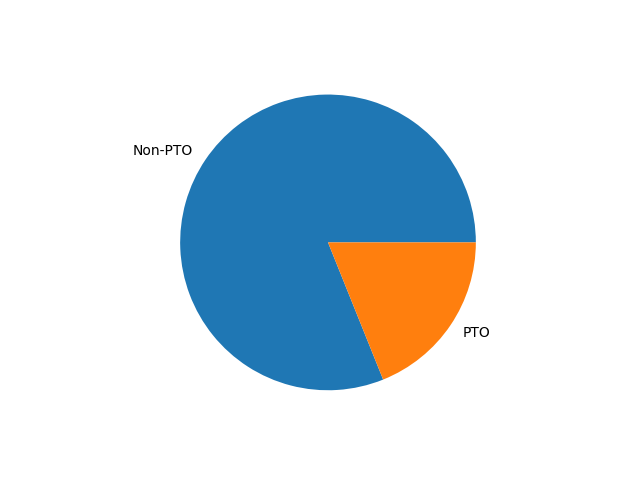
To address the class imbalance, we opted to use oversampling techniques, specifically through Text Augmentation. Text augmentation allowed us to artificially generate more examples for the datapoints, helping balance the dataset. For this, we selected the textattack module due to its ease of use and the pre-built augmentation recipes it offers. In the next section, we’ll dive into the specific text augmentation techniques we explored.
Text Augmentation Techniques
We experimented with two text augmentation techniques:
a. Word embedding augmentation
b. Back Translation
a. Word Embedding Augmentation
Word embedding augmentation replaces a word with another that is semantically similar, based on their proximity in the vector embedding space. This technique uses pre-trained word embeddings (such as Word2Vec, GloVe, or fastText) to map words into high-dimensional vectors. By selecting words close to the original word in this vector space, we can generate alternative expressions with similar meanings. This approach increases the diversity of the dataset while preserving the integrity of the underlying semantics, ultimately enhancing the model’s ability to generalize.
from textattack.augmentation import EmbeddingAugmenter embed_augmenter = EmbeddingAugmenter(pct_words_to_swap=0.3) text = "I am taking PTO today" print(embed_augmenter.augment(text)) ## Output ['I am taking PTO thursday'] |
We experimented with different values for pct_words_to_swap (the percentage of words to swap) and found that setting it to 30% produced better results than values below 30% or above 50%. Additionally, using transformations_per_example=n produced n different augmented outputs for each example.
b. Back Translation
Back Translation is a data augmentation technique where a sentence is first translated from the source language (e.g., English) into another language, such as French or Spanish. The text is then translated back into the original language. This process often results in a slightly modified version of the original sentence, as different words or structures may be used during translation. Back translation helps generate new variations of the data and increase the diversity of the training set.
import nlpaug.augmenter.word as naw aug = naw.BackTranslationAug() text = "I am taking PTO tomorrow" aug.augment(text) ## Output ["I'll take the PTO tomorrow"] |
While Back Translation worked effectively with short sentences, it struggled to produce meaningful variations for longer, more complex sentences. With shorter text, the translation process typically maintains the original meaning and structure, which leads to useful augmented data. However, when we applied it to longer sentences, the back-and-forth translation often caused significant changes in wording or structure, with words being repeated too many times.
text = "I have planned for a PTO break from Oct 19th to 23rd In December tentatively last week Would confirm dates as we approach closer" print(aug.augment(text)) ## Output ['I have scheduled a PTO break for the period from 19 to 23 October, and last week in December, as a precaution last week would confirm the dates when we get closer to the date. I will be the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of the date of |
Oversampling Techniques
To address the class imbalance and increase the number of data points, we explored several data augmentation strategies. By applying these techniques, we were able to generate better balanced and robust datasets, which we then used to train our models. Below are the specific strategies we experimented with and the resulting datasets we used to power our model training efforts:
1. Oversampling the minority class
2. Random oversampling
3. No oversampling (baseline)
1. Oversampling Minority Class
To tackle the class imbalance in our dataset, we chose to apply the word augmentation technique specifically to the minority class. By generating additional variations of the minority class data, we were able to increase its representation in the dataset. As a result, the ratio of minority-to-majority class data points improved significantly, moving from a 1:4 imbalance to a much more balanced 2:3 ratio. Here’s a pie chart showing the new composition of each class
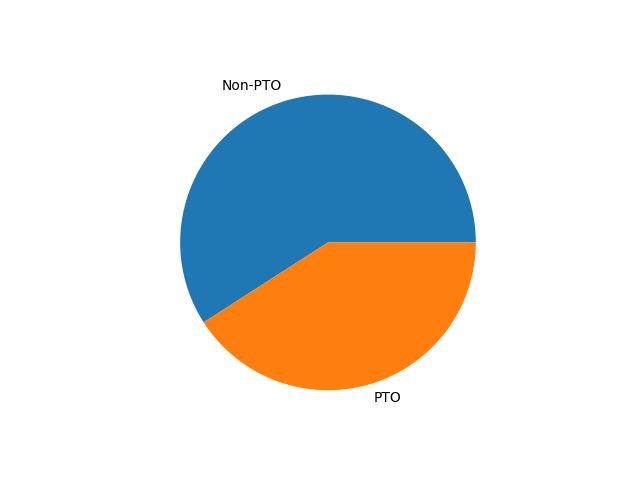
Once we augmented the dataset, we moved forward with fine-tuning the BERT model using this augmented data.
2. Random Oversampling
As an alternative strategy, we employed random oversampling, where we augmented every 4th data point in the dataset, irrespective of its class. By duplicating these data points, we aimed to provide the model with more examples to learn from.
3. No Oversampling
For comparison, we also trained a fine-tuned model using the original dataset without any oversampling, ensuring that it reflected the true class distribution. This model acted as a baseline or benchmark, providing a point of reference for assessing the performance improvements of the oversampled models. By comparing the results of this model with those of the oversampled versions, we could better understand the impact of different data augmentation strategies on model accuracy and generalization.
Evaluating Models
Our goal was to classify messages into two categories: PTO messages and non-PTO messages. To evaluate the performance of the three fine-tuned models, we prepared a balanced test dataset. For each model, we calculated Accuracy, Precision, Recall, and F1 scores.
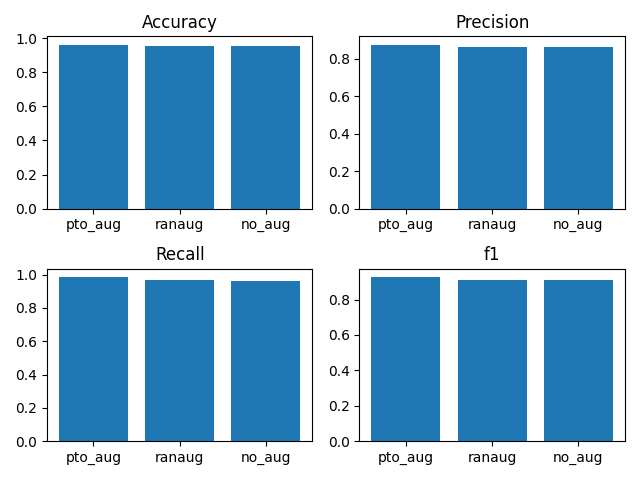
Note: We weren’t surprised that the metrics for all three models were closely aligned, because we used the BERT model which was already trained on a large text corpus and although we applied oversampling, the dataset size still remained relatively small.
Our primary objective was to ensure that we identified all PTO messages, even if it meant occasionally misclassifying non-PTO messages as PTO. Since we were more concerned with identifying all PTO messages—accepting some false positives, therefore, we emphasized recall over precision and selected the model trained with the dataset where the focus was on augmenting the minority class.
Working on this problem gave us valuable insights into the complexities of the data preparation phase of model fine-tuning, highlighting how critical it is to properly balance and preprocess the dataset before training. We also gained a deeper appreciation for the importance of selecting the right evaluation metrics, as these metrics directly influence the decision-making process when choosing the best-performing model. As the next step, we decided to tune the hyperparameters to study their effects on model performance.
Advanced ML testing from Qxf2
Qxf2 offers specialized QA for AI/ML models, helping startups validate their models with robust testing strategies. We understand the workflows of data scientists and ML engineers, allowing us to collaborate effectively and design tests that align with real-world usage. Whether you’re building your first ML pipeline or scaling an existing one, Qxf2 provides the right testing expertise to support your growth. Write to [email protected] to know more.
My expertise lies in engineering high-quality software. I began my career as a manual tester at Cognizant Technology Solutions, where I worked on a healthcare project. However, due to personal reasons, I eventually left CTS and tried my hand at freelancing as a trainer. During this time, I mentored aspiring engineers on employability skills. As a hobby, I enjoyed exploring various applications and always sought out testing jobs that offered a good balance of exploratory, scripted, and automated testing.
In 2015, I joined Qxf2 and was introduced to Python, my first programming language. Over the years, I have also had the opportunity to learn other languages like JavaScript and Shell scripting (if it can be called a language at all). Despite this exposure, Python remains my favorite language due to its simplicity and the extensive support it offers for libraries.
Lately, I have been exploring machine learning, JavaScript testing frameworks, and mobile automation. I’m focused on gaining hands-on experience in these areas and sharing what I learn to support and contribute to the testing community.
In my free time, I like to watch football (I support Arsenal Football Club), play football myself, and read books.

