Why this post?
I’ve always been wondering how Machine learning models functions as black boxes, making predictions based on patterns learned from data. Despite the impressive accuracy, understanding the factors and features that influenced a particular prediction and the decision-making process is crucial and challenging task. The lack of transparency in these models adds complexity making their internal workings less accessible and interpretable.
In this blog post, I’ll explore the use of LIME (Local Interpretable Model-agnostic Explanations) to shed light on the decisions made by a text classification model. LIME is a powerful tool for providing interpretable explanations for machine learning models, acting as a link between complex models and human intuition. It provide insights into the model’s decision-making process by highlighting influential words and their weights.
Why LIME?
LIME proves particularly beneficial for testers in various ways.
How LIME works
LIME works by using an interpretable model to approximate the behavior of the black-box model. It achieves this by generating perturbed instances around a given data point, obtaining predictions from the black-box model, and training a simple model to mimic these predictions. The interpretable model provides insights into the local behavior of the black box model.
Testing our Text Classification Model with LIME
Let’s delve into a practical example. We at Qxf2 have a text classification model(PTO Detector) specifically designed for identifying PTO messages. While testing our test classification model, we encountered few scenarios where despite clear indications of taking time off, the model incorrectly classified certain messages as non-PTO. This misclassification and discrepancy in the predictions alerted me to explore deeper into the model’s decision-making process. From a human intuition point of view, I strongly believe that these messages should be classified as PTO whereas the model identifies them as non-PTO. In the following sections, I will focus on the specific data points where the model’s predictions are wrong and how LIME helped in providing insights into the model’s decision-making.
PTO detector: Text classification model
Our dataset PTO_messages.csv is a collection of text messages for Paid Time Off (PTO) and non-PTO. The labels denote binary classification, with 0 representing not PTO and 1 representing PTO messages. Our PTO detector model is trained on LinearSVC model to classify a message as PTO or non-PTO. The model is serialized into a binary file (pto_classifier.pickle) for convenient storage and retrieval. You can find the pickled model file here.
Applying LIME on PTO Detector model
The below script uses the LimeTextExplainer from the LIME library to provide explanations for predictions on our model. The model is loaded from a pickle file using load_model() function as shown below. The function explain_pto_prediction() takes the model and the text sample as parameters. It preprocesses it by stemming and then uses LIME to explain the model’s prediction.
if __name__ == '__main__': text_sample = "I'm much better today but extremely weak. Will hopefully resume work from Monday" model = load_model(MODEL_FILENAME) explanation = explain_pto_prediction(model, text_sample) explanation.save_to_file('lime_results.html') |
To use LIME with text classifiers, you’ll need to create a LimeTextExplainer object and then generate explanations for specific data sample.
def explain_pto_prediction(model, text): cleaned_text = preprocess_text(text) explainer = LimeTextExplainer(class_names=['0', '1']) explanation = explainer.explain_instance(cleaned_text, model.predict_proba, num_features=50, num_samples=100) return explanation |
Generate an explanation using the explain_instance method, which takes the instance and a function that returns class probabilities(predict_proba()) as parameters. The results are printed and saved to an HTML file for further analysis. Here is the complete code
import os import pickle import re from lime.lime_text import LimeTextExplainer from nltk.stem import SnowballStemmer from nltk.corpus import stopwords NOT_STOP_WORDS = ['not','off','be','will','before','after','out'] ADD_STOP_WORDS = ['today', 'tomorrow', 'yesterday'] # Set up logging configuration CURRENT_DIRECTORY = os.path.dirname(__file__) MODEL_FILENAME = os.path.join(CURRENT_DIRECTORY, 'pto_classifier.pickle') def load_model(model_filename): """Load a trained text classification model from a file.""" try: model = pickle.load(open(model_filename, 'rb')) return model except FileNotFoundError: print (f"Model file not found: {model_filename}") raise def preprocess_text(text): """Preprocess the input text by removing stopwords, stemming, and converting to lowercase""" stemmer = SnowballStemmer('english') words = stopwords.words("english") for word in NOT_STOP_WORDS: words.remove(word) for word in ADD_STOP_WORDS: words.append(word) return " ".join([stemmer.stem(i) for i in re.sub("[^a-zA-Z]", " ", text).split() if i not in words]).lower() def explain_pto_prediction(model, text): """Generate an explanation for the model's prediction using LIME""" cleaned_text = preprocess_text(text) explainer = LimeTextExplainer(class_names=['0', '1']) explanation = explainer.explain_instance(cleaned_text, model.predict_proba, num_features=50, num_samples=100) return explanation if __name__ == '__main__': text_sample = "I'm much better today but extremely weak. Will hopefully resume work from Monday" model = load_model(MODEL_FILENAME) explanation = explain_pto_prediction(model, text_sample) explanation.save_to_file('lime_results.html') |
Now, let’s delve deeper into these instances of misclassification, using LIME explanations.
Usecase 1
Taking unplanned PTO in order to travel home town
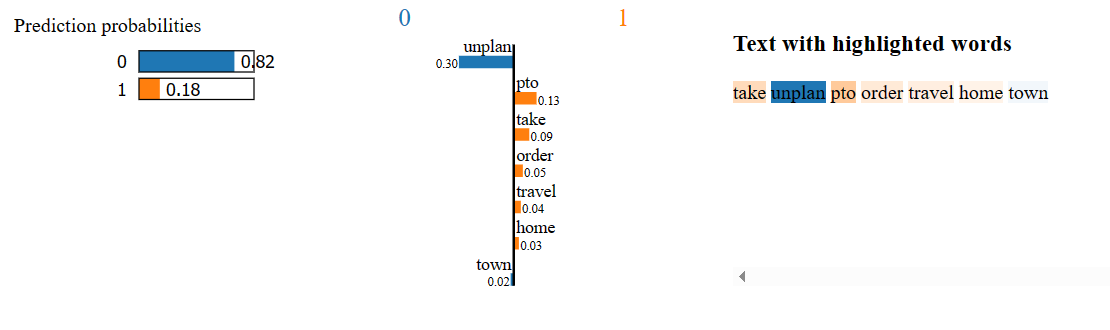
For this sentence, the model predicted as ‘0’ whereas it is actually a PTO message. Lets see the highlighted words that contributed to the model’s prediction. Each word is assigned weight, showing its influence on the prediction. A weight of 0.30 for “unplan” towards class ‘0’ suggests that the model considers the presence of the word “unplan” as indicative of a non-PTO message. The model, having learned from the training data, interprets the presence of “unplan” as suggestive of a non-scheduled or unplanned activity.
Interestingly, the training data shows an equal association of “unplan” with messages of both class 0 and class 1. But the word ‘unplanned’ appears very rarely in the training data set. And so, it is not surprising that the model has trouble classifying it correctly.
Usecase 2
Thank you all. I am feeling better but still not completed recovered, will be taking off today too

For this sentence, the model strongly leans towards classifying the message as non-PTO with a high probability of 0.96. The highlighted words imply that the presence of words like “thank,” and “better,” may be influencing the model to predict a non-PTO message which also indicates a positive sentiment associated with not taking time off. Despite the mention of “still not completely recovered,” the model seems to focus on intention not to take off. The model is primarily driven by the positive sentiment expressed (“thank,” “better”).
This could indicate that the presence of expressions of gratitude and improvement such as “thanks” might be associated with non-PTO messages in the training data.
Usecase 3
I have to stepout for personal emergency bank work. Will resume my work as soon as I return. If it’s get too late will mark as PTO

The model prediction for this sentence leans heavily towards classifying it as non-PTO with a probability of 0.73. This sentence is bit tough to predict, because it doesn’t clearly convey anything either PTO or Not PTO. The words “soon,” “return,” and “resume” is observed in messages where the person is not taking time off. Also, the words like “step out” may imply a short break but not necessarily leave. The ambiguity in the message makes it difficult to clearly categorize it as either PTO or non-PTO. However, from a human intuition point of view, I interpret the message as indicating an unplanned absence.
Usecase 4
I have still not recovered fully, unable to work today as well

In this sentence, the words “recov”,”fulli” and work are assigned high weights indicating that their presence contributes to the prediction of class 0 (Non-PTO). The model might have learned from the training data that expressions related to recovery are more likely associated with non-PTO messages. From a human intuition perspective and by looking at the training data, the word “unable” is mostly associated with PTO. It should play a more significant role in predicting a message as PTO. The model, however, assigns a weight of 0.00 to “unable,” indicating that the model may not have effectively learned the association between “unable” and PTO during training and this is a bug in the model training.
Usecase 5
I’m much better today but extremely weak. Will hopefully resume work from Monday

This sentence is actually a PTO message but surprisingly the model predicts it as a Not PTO message. The words “hope”, “work”, “resume” and “better” are assigned weights of label 0 classifying the message as Not PTO. The model seems to prioritize these words over the mention of weakness, contributing to its misclassification of the message as non-PTO.
The word “will” should have been a stop word i.e., a small bug that would require us to examine the stop words more carefully for more issues and misses.
Usecase 6
Having played around with LIME, I got some human intuition into the model. I was able to figure out some of the model’s weaknesses and come up with some testing ideas to illustrate the problems and imbalances in the training data. For example, I noticed that the word “off” and “taking” contributed significantly towards a sentence being classified as a PTO message. Which lead to this next attempt.
The airline will be taking off in 15 minutes

This sentence is actually a Not PTO message but the model misclassified as a PTO. The model’s prediction seems to be influenced by the presence of words “taking” and “off”. This word has a strong connection with class 1 (PTO) in the training data. This misclassification highlights a potential limitation in the model’s ability to understand the context within the sentence. The phrase “taking off” is not linked to various scenarios, such as going on a trip, leaving work early etc, in the training data and the model could not understand the different context in which this phrase can be used. The frequency and context in which these phrases appear in the training data also play a crucial role.
Conclusion
As a tester, this analysis helped understand
References
1. Build a LIME explainer dashboard with the fewest lines of code
2. Exploring LIME: A Window into the Black Box of Deep Learning
3. Fine-grained Sentiment Analysis in Python (Part 2)
4. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier
Hire testers from Qxf2
Hire technical testers from Qxf2. Our QA engineers go well beyond traditional test automation. We have a wealth of experience in testing critical parts of complex systems. We work well with small teams and early stage products. Get in touch with us to hire technical testers for your product.

I am an experienced engineer who has worked with top IT firms in India, gaining valuable expertise in software development and testing. My journey in QA began at Dell, where I focused on the manufacturing domain. This experience provided me with a strong foundation in quality assurance practices and processes.
I joined Qxf2 in 2016, where I continued to refine my skills, enhancing my proficiency in Python. I also expanded my skill set to include JavaScript, gaining hands-on experience and even build frameworks from scratch using TestCafe. Throughout my journey at Qxf2, I have had the opportunity to work on diverse technologies and platforms which includes working on powerful data validation framework like Great Expectations, AI tools like Whisper AI, and developed expertise in various web scraping techniques. I recently started exploring Rust. I enjoy working with variety of tools and sharing my experiences through blogging.
My interests are vegetable gardening using organic methods, listening to music and reading books.

