Recently we set out to explore how we could fine-tune a code LLM on our Test Automation Framework. During our research, we came across Hugging Face’s excellent guide on Fine-tuning a Code LLM on Custom Code, which provided a clear path, but required access to an A100 GPU. While that hardware requirement is reasonable for serious fine-tuning, we wanted to experiment with a more accessible setup. That led us to unsloth, a project focused on making fine-tuning efficient and possible even on limited hardware. At that point, we pivoted slightly: instead of tuning a raw code model, we decided to fine-tune an instruct model that could answer questions about our framework, using its documentation and wiki as training data. In this post, we’ll walk you through how we used Unsloth to fine-tune a model using the wiki content from our Test Automation Framework
Resourceful fine-tuning using QLoRA
Full-scale fine-tuning of large language models demands extensive computational resources. But Unsloth significantly reduces memory usage by up to 70%, while maintaining model accuracy. It achieves this efficiency through advanced techniques like LoRA(Low Rank Adaptation) and QLoRA( Quantized Low Rank Adaptation. These methods enable models to adapt to new tasks without modifying the original pre-trained weights. Instead, small trainable matrices, called adapters, are introduced into the model, and only these are updated during training. This selective training drastically cuts down on both memory and computational overhead compared to full fine-tuning. At inference time, the model combines its original weights with the trained adapters to produce results.
Fine-Tuning an LLM on Qxf2’s Test Automation Knowledge
We set out to fine-tune a large language model (LLM) to accurately answer questions related to Qxf2’s Test Automation Framework. The unsloth-notebooks served as an excellent starting point, acting as a blueprint for the entire fine-tuning process. We made a few adjustments to tailor the recipe notebook to our specific use case. The Fine-tuning Guide from unsloth was comprehensive, covering all essential steps and considerations for the process.
Our workflow largely followed the recipe notebook with some minor modifications:
1. Model selection
Choosing the right model is a crucial first step when fine-tuning with Unsloth. Unsloth provides recipe notebooks for a variety of models, complete with step-by-step instructions. We initially selected the quantized 4-bit version of unsloth/Llama-3.2-3B-Instruct as our base model and fine-tuned it for our use case. The results were promising—it accurately answered most of our test automation-related questions. However, once we learned that Qwen3 was supported for fine-tuning on Unsloth, we switched to Qwen3 as our new base model to take advantage of its capabilities.
2. Dataset prepration
We used the text data from Qxf2’s Test Automation Framework Wiki. We used ChatGPT to help generate multi-turn conversation-style data to simulate real-world interactions.
Here’s an example from our dataset:
{ "content": "What is Qxf2's test automation framework designed for?", "role": "human" }, { "content": "Qxf2's test automation framework is a Python-based solution for automating web, mobile, and API testing, helping testers write robust tests quickly.", "role": "assistant" } `` |
Since the Unsloth recipe primarily uses only the assistant responses, we applied text augmentation techniques to create three variations of each conversation to enrich the dataset. You can find the complete dataset here: Multi-turn conversation dataset on Qxf2’s Test Automation Framework. Other data preparation steps were left unchanged from the original notebook.
Note: We were unsure of OpenAI’s terms regarding dataset generation using ChatGPT. However, since this was a research-driven exploration of the tool, we proceeded assuming it would fall within acceptable usage.
3. Tuning hyperparameters
We tuned a couple of hyperparameters after several iterations and based on model performance. Most default settings were retained, except for increasing the number of epochs to 3 and commenting out the max_steps parameter.
4. Saving the model
We chose to export the final model in the GGUF format, making it compatible with tools like
Ollama. After updating the HF_TOKEN in the notebook, we ran the recipe with our customizations. The notebook also allows for test prompts before saving, this helped validate and adjust hyperparameters before final export. Once complete, we pushed the trained model to Hugging Face. Here is our model on Hugging Face – Qxf2 Wiki model.
You can access the modified Colab notebook used for this project here – Qwen3-Qxf2-wiki-notebook
Running the Fine-Tuned Model Locally with Ollama
We downloaded the model locally using
ollama run hf.co/shivaharip/qwen3_qxf2_wiki_GGUF:Q4_K_M |
Once the model was up and running, we tested it by prompting it with questions related to Qxf2’s Test Automation Framework. Here are a few examples:
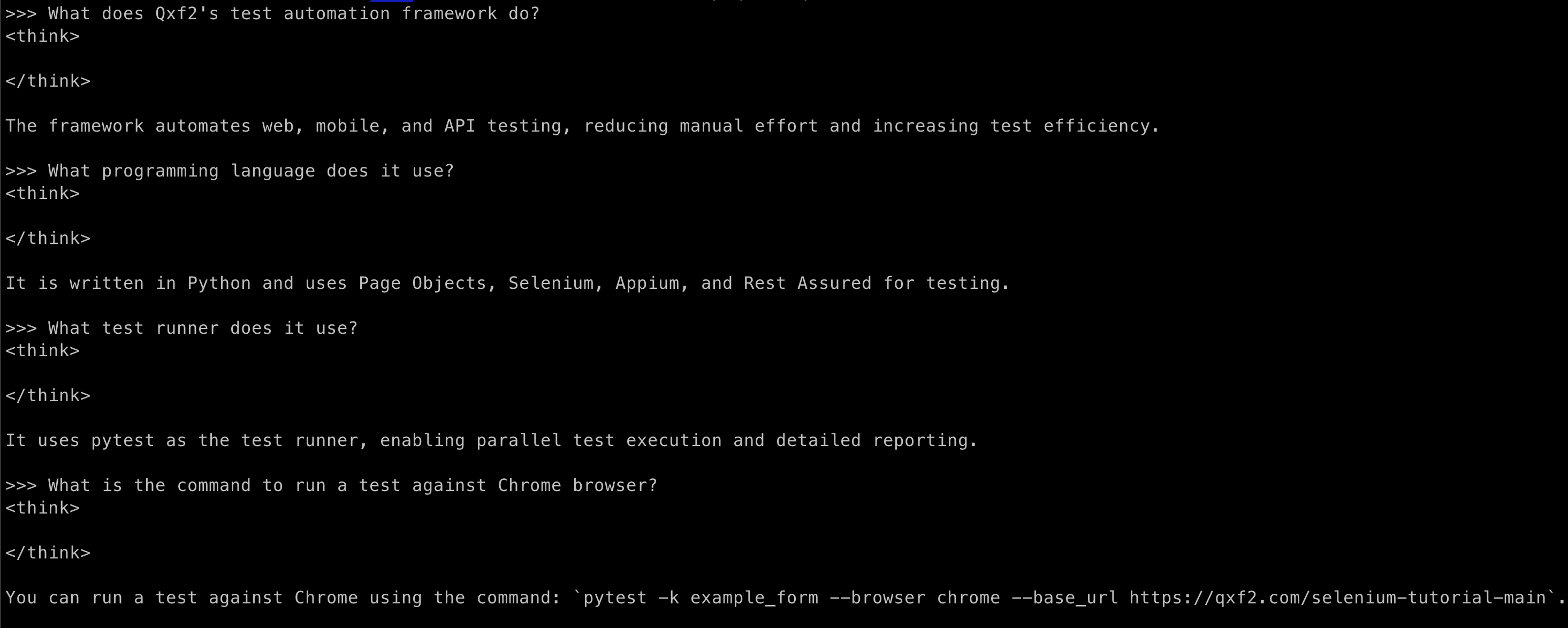
The model handled most knowledge-based queries about the framework accurately, demonstrating its understanding of the fine-tuned content
Reflections and next steps:
The fine-tuned model successfully answered many questions about Qxf2’s Test Automation Framework, but we also noticed a few factual inaccuracies in its responses. These inaccuracies made it clear that effective LLM fine-tuning depends on more than just the tuning process, it requires careful attention to dataset quality, prompt engineering, and hyperparameter optimization to align the model with the target domain. Despite encountering occasional errors, we gained valuable hands-on experience with the QLoRA technique and deepened our understanding of the complexities involved in adapting pre-trained models to domain-specific tasks. We discovered how to fine-tune models efficiently using limited hardware, thanks to tools like Unsloth, LoRA, and QLoRA.
Looking ahead, we plan to:
– Tune hyperparameters further based on the model’s performance and user feedback.
– Refine and expand the dataset to cover more edge cases and diverse phrasing.
– Evaluate the model using a broader range of prompts to improve its reliability and factual accuracy.
– Explore ways to scale this fine-tuning approach to other internal tools or documentation at Qxf2.
– This project marks a promising beginning, and we’re excited to keep improving the model’s accuracy and usefulness in real-world testing scenarios.
Advanced ML testing from Qxf2
At Qxf2, we provide custom QA solutions for AI and ML systems, helping startups validate their machine learning workflows through proven and dependable testing strategies. Our team actively explores emerging tools to stay hands-on with the latest advancements in the field. We bring this practical knowledge to ensure the quality and reliability of our client’s AI/ML solutions. To know how we can help, reach out to [email protected].
My expertise lies in engineering high-quality software. I began my career as a manual tester at Cognizant Technology Solutions, where I worked on a healthcare project. However, due to personal reasons, I eventually left CTS and tried my hand at freelancing as a trainer. During this time, I mentored aspiring engineers on employability skills. As a hobby, I enjoyed exploring various applications and always sought out testing jobs that offered a good balance of exploratory, scripted, and automated testing.
In 2015, I joined Qxf2 and was introduced to Python, my first programming language. Over the years, I have also had the opportunity to learn other languages like JavaScript and Shell scripting (if it can be called a language at all). Despite this exposure, Python remains my favorite language due to its simplicity and the extensive support it offers for libraries.
Lately, I have been exploring machine learning, JavaScript testing frameworks, and mobile automation. I’m focused on gaining hands-on experience in these areas and sharing what I learn to support and contribute to the testing community.
In my free time, I like to watch football (I support Arsenal Football Club), play football myself, and read books.

