I set out to evaluate a ML model (emotion classifier) from a human/user perspective. The heart of my attempt was going to be around designing the right set of data to evaluate the performance of the model. Very quickly, I realized that there is more to this task than meets the eye. In this post, I will share several problems (and intuitive solutions) that testers are bound to encounter when they need to evaluate ML models and their performance from a user’s perspective. Any tester who is contemplating effective methods for testing a constantly improving ML model will gain benefits from this post.
At the outset, I want to clarify that this post has two aspects:
a) a technical aspect around designing data and writing code to evaluate the model output
b) a social aspect that involves the entire team contributing to creating test data
Note: The dataset I am talking about is different from what a data scientist/ML engineer will use to train their data. The dataset I needed was purely for the QA team to use as part of our tests. We would use the model’s score against this dataset as a baseline. That way, we would know build over build if the model’s performance got better or regressed.
Problem Statement
I wanted to evaluate how well the Roberta, Bert base cased, Bert base uncased models performed for emotion classification. Typically, you can give a sentence as an input and the model would spit out the emotion attached with the sentence. Now, understanding this becomes really tricky from a human perspective, as some sentences can be interpreted to convey more than one emotion.
For example – “I can’t believe you would betray my trust like that” can be interpreted as both annoyance and disappointment.
This was the starting point for me to find a way to have a dataset with multi label.
Training Datasets
I wanted to understand on what datasets was the above models being trained on. Because that would give me a baseline to create my own datasets. I looked up hugging face and found that it had been trained on goemotion dataset. I also had to look up the dataset to understand what all labels I could expect as output from the model. The goemotion has 28 parameters as shown below.
goemotion parameters
admiration anger annoyance approval caring confusion curosity desire dissapointment disapproval disgust embarrassement excitement fear gratitude grief joy love nervousness optimism pride realization relief remorse sadness surprise neutral |
Is the dataset a fair way to evaluate the model?
I have been seeing that most of the emotion classifier datasets were using only single label but I felt that with just only a single label, it would not be a fair way to evaluate the model because a sentence could be interpreted in more than one way by humans and model. So, how do we know if the model have produced a correct or incorrect output if we don’t have a diverse labeling for a sentence? This is where a multi label dataset would help.
Design a small but ‘human’ dataset
I initially started reading papers to understand how the dataset were designed like the one mentioned in the above section. I found that most of the datasets were designed from openly available sentences like tweets and reddit comments whereas I wanted to create a small, but very human looking dataset to evaluate the model’s performance which is different than the training dataset.
Also, no matter where we go, testers will have to design data sets. But that is a cumbersome, tricky and thankless task. So we needed to figure out a way to involve everyone in the company.
Involving everyone for this task was an important step in my mind to understand how diverse can the sentences be interpreted by different humans. I as an individual could have also multi labeled the data but that would have a pinch of biasness and also I feel that would not be a fair way to create the dataset.
So, we at Qxf2 came together for this task. I initially prepared the dataset with 82 data and had an initial meeting with one of our colleague about the quality of the data. After reviewing the quality of the sentences, I held a team discussion.
The first group of five members was assigned to multi-label the first 41 sentences, while the second group of five members was assigned to multi-label the next 41 sentences.
I was amazed to see how differently a sentence can be interpreted by different people. That’s why we created this dataset with multiple labels.
For instance, it’s worth noting how a sentence can be interpreted and classified differently by different individuals.

The dataset is available here
Results
I wanted to check how including the multi labels have had an impact on performance improvement on the 82 sentences because with only single label, it sometimes get difficult as a tester to convince that the model has wrongly classified sentences. I wanted to minimize this argument with a multi label dataset. Please see the results below.
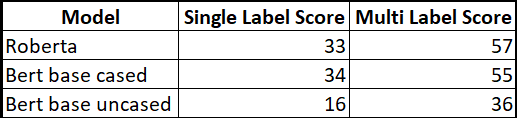
The result shows the difference for model evaluation on the same dataset of 82 sentences for single label and multi label for all the 3 models. The result clearly demonstrates how the model enhanced its score when we multi-labeled the same sentences.
Code to test with multi labels
To test the dataset with multi labels, I created a simple python script to calculate the score for all the 3 models for Single and Multi label.
First, I ran the script with single label with that of the label generated by the model. If the label matches, I give it a score as 1 else 0. Next, for multi label I match each labels, labeled by our team with the label that the model generates. If the label generated by the model matches any of the team’s labels, we give it a score of 1. Otherwise, it gets a score of 0.
Code Snippet
'''importing the csv module''' import csv def calculate_score(team_label, model_label): '''Function to calculate the score''' for word in team_label: if word in model_label: return 1 return 0 # Read data from CSV file FILENAME = 'consolidated_emotion_classifier_multi_label.csv' # Column names COLUMN_LABELS = ['label1', 'label2', 'label3', 'label4', 'label5', 'label6', 'label7'] COLUMN_UNCASED = 'Roberta model Label' SCORES = [] with open(FILENAME, 'r', encoding="utf-8") as file: csv_reader = csv.DictReader(file) for row in csv_reader: TEAM_LABEL_VAR = [row[label_column] for label_column in COLUMN_LABELS] MODEL_LABEL_VAR = row[COLUMN_UNCASED].split() SCORE = calculate_score(TEAM_LABEL_VAR, MODEL_LABEL_VAR) SCORES.append(SCORE) for index, SCORE in enumerate(SCORES, start=1): print(f"Text {index} Score: {SCORE}") |
Conclusion
This post might seem simple, but there are several practical tips that you, as a tester, can take away from this post:
1. Design a small dataset for QA purposes
2. Use the model performance against the dataset to compare builds
3. Involve the entire team in creating the dataset
4. Adjust your dataset to allow for multiple “correct” interpretations
I would love to hear from you if you have attempted something similar in you ML projects.
Hire QA engineers from Qxf2 for your ML projects
Qxf2 has a proven track record of working extensively with ML models, handling data validation, performance evaluation, and more. We use modern testing tools to identify potential biases, ensure data quality, validate ML pipelines – curcial aspects of testing that are often overlooked in ML projects. Get in touch with us to hire experienced testers for your ML projects.
My journey in software testing began with Calabash and Cucumber, where I delved into Mobile Automation using Ruby. As my career progressed, I gained experience working with a diverse range of technical tools. These include e-Discovery, Selenium, Python, Docker, 4G/5G testing, M-CORD, CI/CD implementation, Page Object Model framework, API testing, Testim, WATIR, MockLab, Postman, and Great Expectation. Recently, I’ve also ventured into learning Rust, expanding my skillset further. Additionally, I am a certified Scrum Master, bringing valuable agile expertise to projects.
On the personal front, I am a very curious person on any topic. According to Myers-Briggs Type Indicator, I am described as INFP-T. I like playing soccer, running and reading books.

