Ever wondered if your XPath is good enough? Did your XPath break for any minor changes made in the webpage? Did your XPath return a different element? If your answer to one of those questions is yes, then this is the right post for you.
Why this post?
While learning to write XPaths, I made a few mistakes that were corrected during our code review. I noticed the same mistakes being made elsewhere when searching on the web for solutions. This made me realize some of the mistakes I made were very common. I decided to document these mistakes to help budding automation testers.
**Note: Firebug,XPath Checker and Selenium IDE are used to emphasize the concepts with examples.
Common XPath mistakes
We will journey through five common XPath mistakes by playing along with
one example -identifying a table cell with text 7878787878 element in the Example Table of this page. At each stage, we will show you how each mistake looks and suggest an improvement. At the end of the five mistakes, you will have a good XPath to use.
Obviously this is a slightly contrived example but it is intended to highlight common mistakes with just one example.
Mistake 1: Using Selenium IDE to find XPath:
So many testers blindly use the selector suggested by Selenium IDE. Selenium IDE is smart enough to figure out an element’s XPath while recording an action. But the XPath is usually brittle when the element has no unique identifier. If you take away one thing from this post – it is this: stop using Selenium IDE for writing XPaths. Make an effort to write your own!
Mistake 2: Starting with the root node:
Some testers start an XPath from the root node. Though it shows that the tester knows what he is doing, it is advised not to start from the root node. Webpages are prone to changes. If any change is made in the structure it might require the XPath be revised. The absolute XPath is not used for this reason.
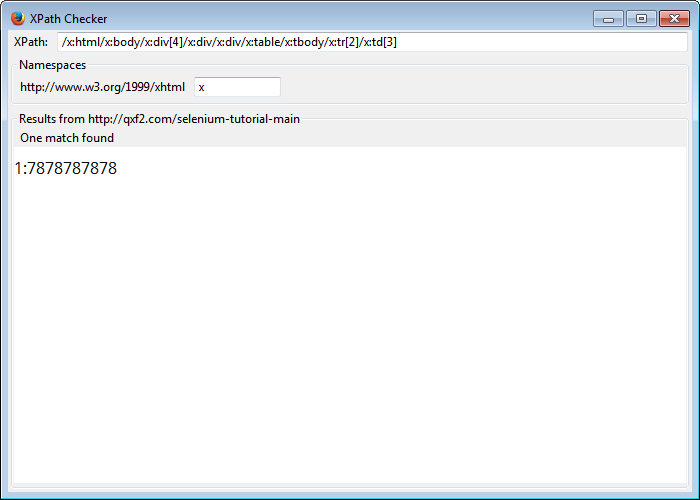
As we can see in the above example, the XPath starts from the html tag. This XPath is very brittle as the introducing any new element or reordering elements in the page would render it useless.
Mistake 3: @class has an ‘=’ in condition:
CSS classes are used to style elements. So a typical element can have multiple CSS classes in its class attribute. By using ‘@class=’ your XPath is vulnerable to a developer adding an extra class or even just changing the order of the class names. In both cases, your GUI automation should probably not change. But if you use ‘@class=’ in your XPaths, it is likely that your automation will fail for no good reason. It is better to use the condition contains(@class,’value’) instead.(NOTE: There are cases when you want to check for exact style, in which case, @class=’value’ is good!)
BAD:
//table[@class = 'table table-striped']/tbody/tr[2]/td[3] |
Tomorrow, if the developer changes the table’s class so that the color of the text in tables is different, our identifier should still be able to locate the text we want.
BETTER:
//table[contains(@class ,'table-striped')]/tbody/tr[2]/td[3] |
Mistake 4: Having two elements one after the other:
A common mistake while writing XPaths is to use one element after the other. This is not advised as any insertions into the HTML dom between the element and its descendant, could make the identifier obsolete.
BAD:
//table[contains(@class ,'table-striped')]/tbody/tr[2]/td[3] |
BETTER:
//table[contains(@class , 'table-striped')]/descendant::td[7] |
It is better to use the XPath axis descendant instead.
Mistake 5: Using indices to explicitly identify an element:
Using indices is another commonly made mistake while creating an XPath. Indices are not resistant even to the minor changes in the webpage. If the order in which the data in the table is displayed is changed then the XPath which worked fine previously may not be able to locate the same element.
BAD:
//table[contains(@class , 'table-striped')]/descendant::td[7] |
While the above would still find the required element,the XPath becomes more robust with the use of text() function to refer the corresponding element rather than an index. Thus the final XPath we have arrived at more different than the one we started with.
BETTER:
//table[contains(@class , 'table-striped')]/descendant::td[contains(text(),'7878787878')] |
I’ll point out that there are going to be occasions when these are not necessarily mistakes. In fact, in some cases these may be your only option. In those cases, lay out the reasons for why the XPath is brittle and consider working with your developers to get better identifiers.
Writing a robust XPath is an art. I hope this helps you master the art of writing good XPaths.
Hire Qxf2 for your testing needs
This post was possible due to Qxf2’s commitment to sharing our expertise and helping testers. If you are looking to hire experienced testers who can tackle complex technical challenges, contact us. You will get to work with one of the best companies for startup QA.
My expertise lies in engineering high-quality software. I began my career as a manual tester at Cognizant Technology Solutions, where I worked on a healthcare project. However, due to personal reasons, I eventually left CTS and tried my hand at freelancing as a trainer. During this time, I mentored aspiring engineers on employability skills. As a hobby, I enjoyed exploring various applications and always sought out testing jobs that offered a good balance of exploratory, scripted, and automated testing.
In 2015, I joined Qxf2 and was introduced to Python, my first programming language. Over the years, I have also had the opportunity to learn other languages like JavaScript and Shell scripting (if it can be called a language at all). Despite this exposure, Python remains my favorite language due to its simplicity and the extensive support it offers for libraries.
Lately, I have been exploring machine learning, JavaScript testing frameworks, and mobile automation. I’m focused on gaining hands-on experience in these areas and sharing what I learn to support and contribute to the testing community.
In my free time, I like to watch football (I support Arsenal Football Club), play football myself, and read books.


What is the purpose of using “descendant::” and is it necessary?
The element can be found by using this XPath
“`
//table[contains(@class , ‘table-striped’)]//td[contains(text(),’7878787878′)]
“`
Descendant is used to locate the children and children’s children of the current node.
Although “//table[contains(@class,’table-striped’)]//td[contains(text(),’7878787878′)]” might work, it is always a good practice to use Descendant.
It is like saying your automation that Mr.X lives in this building rather than adding specifics about the flat-no and floor. The perk is that your automation would still locate Mr.X even if he chooses to move to another flat or floor.