At Qxf2 we use BrowserStack to run our automated checks against different browsers. BrowserStack is a cloud-based, cross-browser, testing tool that takes away the pain of maintaining a physical lab and saves us a lot of time.
Why this post?
BrowserStack is a great tool to execute your automated tests. However BrowserStack is not a good tool to report the test results. At our clients, we usually execute our tests on BrowserStack and then report our automated test results to a test case management tool like TestRail or rely on the CI server as the test reporting tool. BrowserStack has useful debug artifacts that we want to share with whatever test reporting system that we integrate with. We especially find the BrowserStack screenshot URLs and the BrowserStack URL for the video replay to be helpful in investigating and reporting failures. We created a BrowserStack library using Python and BrowserStack’s API to help us share these BrowserStack artifacts across our automation framework. We wanted to share it with the testing community.
Overview
We will run a test similar to what we ran in our previous post on BrowserStack. If you need more details on BrowserStack set up and access key please refer to the previous post. We will take one screenshot during the test. BrowserStack saves the screenshot and stores a video recording of the test. We will write a library that will help us access these artifacts and print them out in our test’s log.
Note 1: BrowserStack screenshots are available on Amazon’s S3 for 90 days.
Note 2: BrowserStack’s video recording of your test run is available for 30 days.
So if you are working in a highly risk conscious industry with the chance of being audited, you may want to store these artifacts somewhere else.
A step by step guide
Here are the six steps we will perform:
1. Authenticate
2. Get replay url
3. Get latest screenshot
4. Putting it all together
5. Example usage
6. Running the test
You can use REST API to access information about your tests like build, sessions, session logs etc. We will use Python requests module to achieve this.
Step1. Authenticate
Use your BrowserStack username and access key for authentication
self.auth = ('USERNAME','ACCESSKEY') |
Step2. Get replay url
The replay URL is of form: /builds/$build_id/session/$session_id/. To get the replay URL you need the build id and session id. Let us write methods to get the build id as well as the active session id.
def get_build_id(self): "Get the build ID" self.build_url = self.browserstack_url + "builds.json" builds = requests.get(self.build_url, auth=self.auth).json() build_id = builds[0]['automation_build']['hashed_id'] return build_id def get_sessions(self): "Get a JSON object with all the sessions" build_id = self.get_build_id() sessions= requests.get(self.browserstack_url + 'builds/%s/sessions.json'%build_id, auth=self.auth).json() return sessions def get_active_session_id(self): "Return the session ID of the first active session" session_id = None sessions = self.get_sessions() for session in sessions: #Get session id of the first session with status = running if session['automation_session']['status']=='running': session_id = session['automation_session']['hashed_id'] break return session_id def get_session_url(self,session_id): "Get the video URL from build and session details. Needs to be called after session is completed" build_id = self.get_build_id() self.build_session_url = self.browserstack_url + "builds/"+build_id+"/sessions/"+session_id build_session_details = requests.get(self.build_session_url, auth=self.auth).json() #Get the video url from session details video_url = build_session_details[u'automation_session'][u'video_url'] session_url= video_url.encode("utf-8") return session_url |
Step3. Get latest screenshot
This step is a bit of a hack. There is no direct API call to get a list of screenshots saved by BrowserStack. There is no way to explicitly name the image BrowserStack saves on Amazon’s S3. To get past this, we end up parsing the session logs and find the latest screenshot. Then in our test, we can explicitly name and store the screenshot URL.
def get_session_logs(self): "Return the session log in text format" build_id = self.get_build_id() session_id = self.get_active_session_id() session_log = requests.get(self.browserstack_url + 'builds/%s/sessions/%s/logs'%(build_id,session_id),auth=self.auth).text return session_log def get_latest_screenshot_url(self): "Get the URL of the latest screenshot" session_log = self.get_session_logs() #Process the text to locate the URL of the last screenshot screenshot_request = session_log.split('screenshot {}')[-1] response_result = screenshot_request.split('REQUEST')[0] image_url = response_result.split('https://')[-1] image_url = image_url.split('.png')[0] screenshot_url = 'https://' + image_url + '.png' return screenshot_url |
Step4. Putting it all together Library
This is how our library looks.
""" Qxf2 BrowserStack library to interact with BrowserStack's artifacts. For now, this is useful for: a) Obtaining the session URL b) Obtaining URLs of screenshots """ import os,requests class BrowserStack_Library(): "BrowserStack library to interact with BrowserStack artifacts" def __init__(self,credentials_file=None): "Constructor for the BrowserStack library" self.browserstack_url = "https://www.browserstack.com/automate/" self.auth = ('USERNAME','ACCESS_KEY') def get_build_id(self): "Get the build ID" self.build_url = self.browserstack_url + "builds.json" builds = requests.get(self.build_url, auth=self.auth).json() build_id = builds[0]['automation_build']['hashed_id'] return build_id def get_sessions(self): "Get a JSON object with all the sessions" build_id = self.get_build_id() sessions= requests.get(self.browserstack_url + 'builds/%s/sessions.json'%build_id, auth=self.auth).json() return sessions def get_active_session_id(self): "Return the session ID of the first active session" session_id = None sessions = self.get_sessions() for session in sessions: #Get session id of the first session with status = running if session['automation_session']['status']=='running': session_id = session['automation_session']['hashed_id'] break return session_id def get_session_url(self,session_id): "Get the video URL from build and session details. Needs to be called after session is completed" build_id = self.get_build_id() self.build_session_url = self.browserstack_url + "builds/"+build_id+"/sessions/"+session_id build_session_details = requests.get(self.build_session_url, auth=self.auth).json() #Get the video url from session details video_url = build_session_details[u'automation_session'][u'video_url'] session_url= video_url.encode("utf-8") return session_url def get_session_logs(self): "Return the session log in text format" build_id = self.get_build_id() session_id = self.get_active_session_id() session_log = requests.get(self.browserstack_url + 'builds/%s/sessions/%s/logs'%(build_id,session_id),auth=self.auth).text return session_log def get_latest_screenshot_url(self): "Get the URL of the latest screenshot" session_log = self.get_session_logs() #Process the text to locate the URL of the last screenshot screenshot_request = session_log.split('screenshot {}')[-1] response_result = screenshot_request.split('REQUEST')[0] image_url = response_result.split('https://')[-1] image_url = image_url.split('.png')[0] screenshot_url = 'https://' + image_url + '.png' return screenshot_url |
Step5. Example usage
We are going to execute a Selenium test that visits http://www.chess.com/, asserts the title page and then clicks on the Sign up button and then take a screenshot. We will get and print the BrowserStack video replay URL and screenshot URL using the BrowserStack Library we just created.
import unittest, time from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from BrowserStack_Library import BrowserStack_Library class SeleniumOnBrowserStack(unittest.TestCase): "Example class written to run Selenium tests on BrowserStack" def setUp(self): desired_cap = {'platform': 'Windows', 'browserName': 'Firefox', 'browser_version':'65', 'browserstack.debug': 'true' } self.driver = webdriver.Remote(command_executor='http://USERNAME:[email protected]:80/wd/hub',desired_capabilities=desired_cap) self.browserstack_obj = BrowserStack_Library() def test_chess(self): "An example test: Visit chess.com and click on sign up link" # Go to the URL self.driver.get("http://www.chess.com") # Assert that the Home Page has title "Chess.com - Play Chess Online - Free Games" self.assertIn("Chess.com - Play Chess Online - Free Games", self.driver.title) # Identify the xpath for Play Now button which will take you to the sign up page elem = self.driver.find_element_by_xpath("//a[@title='Play Now']") elem.click() self.driver.save_screenshot("test_chess.png") # Print the title print self.driver.title # Get the Browserstack Screenshot url print "BrowserStack Screenshot url :",self.browserstack_obj.get_latest_screenshot_url() # Get the Browserstack active session id active_session_id = self.browserstack_obj.get_active_session_id() print "BrowserStack session id :",active_session_id # Complete the session self.driver.quit() # Get the Browserstack Session/Video url print "BrowserStack Session url :",self.browserstack_obj.get_session_url(active_session_id) if __name__ == '__main__': unittest.main() |
Step6. Run the Test
You can run the test script the normal way you do. We run it via the command prompt.
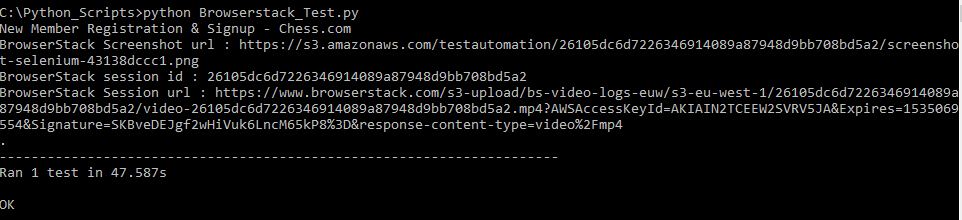
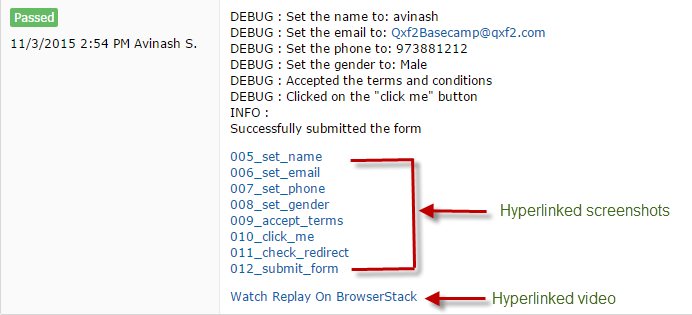
We’ll leave you with a screenshot of how we end up hyperlinking these artifacts when reporting to TestRail.
We plan to write a post (within the next 6 months) showing you how to take screenshots automatically, numbers them intelligently, integrate screenshot naming with BrowserStack and then hyperlinking the artifacts to TestRail. If you are in a hurry to get this information, please post a comment below and we will directly share code with you.

I am a dedicated quality assurance professional with a true passion for ensuring product quality and driving efficient testing processes. Throughout my career, I have gained extensive expertise in various testing domains, showcasing my versatility in testing diverse applications such as CRM, Web, Mobile, Database, and Machine Learning-based applications. What sets me apart is my ability to develop robust test scripts, ensure comprehensive test coverage, and efficiently report defects. With experience in managing teams and leading testing-related activities, I foster collaboration and drive efficiency within projects. Proficient in tools like Selenium, Appium, Mechanize, Requests, Postman, Runscope, Gatling, Locust, Jenkins, CircleCI, Docker, and Grafana, I stay up-to-date with the latest advancements in the field to deliver exceptional software products. Outside of work, I find joy and inspiration in sports, maintaining a balanced lifestyle.


Hi,
Do we have a privilege to download a video of a test run using Rest Api, if yes can you please provide required details.
Thanks,
Anusha
Wonderful integration ! Thanks
Hello. I developed a wrapper for BrowserStack’s API using two methods from this post: get_session_url and get_session_logs. I’d like to publish it on GitHub under MIT license. Can I use them? (attributing the source, of course).
Hi Andre,
You are more than welcome to publish the wrapper on your GitHub.
How to take screenshot of URL which needs authentication?
I want to use BrowserStack Screenshot API.
Hii Dixit,
I think https://www.browserstack.com/question/562 will help you.If not kindly give more description of the issue you are facing.
Hi,
After the test, how to get the screen-shots/video in circleci artifacts
Hi Rao,
You can use your circle.yml file to say which directories need to be placed in the artifacts folder. E.g.: If I store my screenshots in the ./screenshots directory and my logs in the ./logs directory, I would modify the ‘general’ section of my circle.yml to look like the example below
# Sample circle.yml general: artifacts: - "./screenshots" #Save the screenshots for all the tests - "./logs" #Save the logs for all the testsYou can also refer the below link to get the screenshots/video in circle CI artifacts
https://circleci.com/docs/1.0/build-artifacts/
Hey,
It’s great article, but I cant run this, please check bellow:
New Member Registration & Signup – Chess.com
BrowserStack Session url :E
======================================================================
ERROR: test_chess (__main__.SeleniumOnBrowserStack)
An example test: Visit chess.com and click on sign up link
———————————————————————-
Traceback (most recent call last):
File “Test.py”, line 41, in test_chess
print “BrowserStack Session url :”, self.browserstack_obj.get_session_url()
File “C:\development\robot-scripts\test\venv\lib\BrowserStack_Library.py”, line 51, in get_session_url
build_id = self.get_build_id()
File “C:\development\robot-scripts\test\venv\lib\BrowserStack_Library.py”, line 22, in get_build_id
builds = requests.get(self.build_url, auth=self.auth).json()
File “C:\development\robot-scripts\test\venv\lib\site-packages\requests\models.py”, line 892, in json
return complexjson.loads(self.text, **kwargs)
File “C:\development\robot-scripts\test\venv\lib\site-packages\simplejson\__init__.py”, line 518, in loads
return _default_decoder.decode(s)
File “C:\development\robot-scripts\test\venv\lib\site-packages\simplejson\decoder.py”, line 370, in decode
obj, end = self.raw_decode(s)
File “C:\development\robot-scripts\test\venv\lib\site-packages\simplejson\decoder.py”, line 400, in raw_decode
return self.scan_once(s, idx=_w(s, idx).end())
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
———————————————————————-
Ran 1 test in 24.976s
FAILED (errors=1)
Hi Adam,
I did a quick check of my code and it worked fine. Can you please check if you have updated the Username and Access_Key in the BrowserStack Library file?
If yes can you please share your code so that I can debug it.
Many thanks for your reply, Please note that the test are running without problem on Browserstack so credentials should be fine. Especially that it works well if I comment those lines:
#print “BrowserStack Session url :”, self.browserstack_obj.get_session_url()
#print “BrowserStack Screenshot url :”, self.browserstack_obj.get_latest_screenshot_url()
Please look at test code bellow:
import unittest, time
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from BrowserStack_Library import BrowserStack_Library
class SeleniumOnBrowserStack(unittest.TestCase):
“Example class written to run Selenium tests on BrowserStack”
def setUp(self):
desired_cap = {‘platform’: ‘Windows’, ‘browserName’: ‘Chrome’, ‘browser_version’: ‘62.0’,
‘browserstack.debug’: ‘true’}
self.driver = webdriver.Remote(command_executor=’http://username:[email protected]:80/wd/hub’,
desired_capabilities=desired_cap)
self.browserstack_obj = BrowserStack_Library()
def test_chess(self):
“An example test: Visit chess.com and click on sign up link”
# Get the Browserstack sesssion url and Screenshot url
print “BrowserStack Session url :”, self.browserstack_obj.get_session_url()
# Go to the URL
self.driver.get(“http://www.chess.com”)
# Assert that the Home Page has title “Chess.com – Play Chess Online – Free Games”
self.assertIn(“Chess.com – Play Chess Online – Free Games”, self.driver.title)
# Identify the xpath for Play Now button which will take you to the sign up page
elem = self.driver.find_element_by_xpath(“//a[@title=’Play Now’]”)
elem.click()
self.driver.save_screenshot(“test_chess.jpg”)
# Print the title
print self.driver.title
# Get the Browserstack Screenshot url
print “BrowserStack Screenshot url :”, self.browserstack_obj.get_latest_screenshot_url()
def tearDown(self):
self.driver.quit()
if __name__ == ‘__main__’:
unittest.main()
BrowserStack Library code:
“””
Qxf2 BrowserStack library to interact with BrowserStack’s artifacts.
For now, this is useful for:
a) Obtaining the session URL
b) Obtaining URLs of screenshots
“””
import os, requests
class BrowserStack_Library():
“BrowserStack library to interact with BrowserStack artifacts”
def __init__(self,credentials_file=None):
“Constructor for the BrowserStack library”
self.browserstack_url = “https://api.browserstack.com/automate/”
self.auth = (‘username’, ‘Access_Key’)
def get_build_id(self):
“Get the build ID”
self.build_url = self.browserstack_url + “builds.json”
builds = requests.get(self.build_url, auth=self.auth).json()
build_id = builds[0][‘automation_build’][‘hashed_id’]
return build_id
def get_sessions(self):
“Get a JSON object with all the sessions”
build_id = self.get_build_id()
sessions= requests.get(self.browserstack_url + ‘builds/%s/sessions.json’%build_id, auth=self.auth).json()
return sessions
def get_active_session_id(self):
“Return the session ID of the first active session”
session_id = None
sessions = self.get_sessions()
for session in sessions:
#Get session id of the first session with status = running
if session[‘automation_session’][‘status’]==’running’:
session_id = session[‘automation_session’][‘hashed_id’]
break
return session_id
def get_session_url(self):
“Get the session URL”
build_id = self.get_build_id()
session_id = self.get_active_session_id()
session_url = ‘https://www.browserstack.com/s3-upload/bs-video-logs-euw/s3-eu-west-1/%s/video-%s.mp4’%(session_id,session_id)
return session_url
def get_session_logs(self):
“Return the session log in text format”
build_id = self.get_build_id()
session_id = self.get_active_session_id()
session_log = requests.get(self.browserstack_url + ‘builds/%s/sessions/%s/logs’%(build_id,session_id),auth=self.auth).text
return session_log
def get_latest_screenshot_url(self):
“Get the URL of the latest screenshot”
session_log = self.get_session_logs()
#Process the text to locate the URL of the last screenshot
screenshot_request = session_log.split(‘screenshot {}’)[-1]
response_result = screenshot_request.split(‘REQUEST’)[0]
image_url = response_result.split(‘https://’)[-1]
image_url = image_url.split(‘.png’)[0]
screenshot_url = ‘https://’ + image_url + ‘.png’
return screenshot_url
Regards,
Adam
After run it, it returns with this:
FAILED (errors=1)
(venv) C:\development\robot-scripts\aat\demo\Roman_AT>python Test.py
BrowserStack Session url :E
======================================================================
ERROR: test_chess (__main__.SeleniumOnBrowserStack)
An example test: Visit chess.com and click on sign up link
———————————————————————-
Traceback (most recent call last):
File “Test.py”, line 20, in test_chess
print “BrowserStack Session url :”, self.browserstack_obj.get_session_url()
File “C:\development\robot-scripts\test\venv\lib\BrowserStack_Library.py”, line 51, in get_session_url
build_id = self.get_build_id()
File “C:\development\robot-scripts\test\venv\lib\BrowserStack_Library.py”, line 22, in get_build_id
builds = requests.get(self.build_url, auth=self.auth).json()
File “C:\development\robot-scripts\test\venv\lib\site-packages\requests\models.py”, line 892, in json
return complexjson.loads(self.text, **kwargs)
File “C:\development\robot-scripts\test\venv\lib\site-packages\simplejson\__init__.py”, line 518, in loads
return _default_decoder.decode(s)
File “C:\development\robot-scripts\test\venv\lib\site-packages\simplejson\decoder.py”, line 370, in decode
obj, end = self.raw_decode(s)
File “C:\development\robot-scripts\test\venv\lib\site-packages\simplejson\decoder.py”, line 400, in raw_decode
return self.scan_once(s, idx=_w(s, idx).end())
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
———————————————————————-
Ran 1 test in 11.705s
FAILED (errors=1)
Okay 🙂 I’ve ran this properly by clicking play instead of command “python Test.py”
But, how to get into the file if I am getting this from printed xml:
AccessDeniedAccess Denied
BA350562689C5863
oNrAjDH5Y3502IMbAsMGwrkTTz6k0W1g55ek804yyaQTriwBNIDSWZqyJnre7c/0w2btiokmZGs=
{code}
AccessDeniedAccess Denied
BA350562689C5863
oNrAjDH5Y3502IMbAsMGwrkTTz6k0W1g55ek804yyaQTriwBNIDSWZqyJnre7c/0w2btiokmZGs=
”
{code}
Hi Adam,
I noticed that the BrowserStack Session URL which used to be helpful to get the playback URL seems to be broken, hence you are getting Access Denied message.
The BrowserStack Screenshot url seems to be working fine and you should be able to see the test session screenshot using the url. I will update the BrowserStack Session URL logic shortly.
The issue with video url has been fixed. The code should work fine now
Hi ,
I am using protractor & Jasmine. I want to get the video_url only on a test failure.
Do you have any suggestions.
Thanks
Pinky.
Hi,
Have you taken a look at the BrowserStack JS APIs https://github.com/scottgonzalez/node-browserstack.
The session object endpoint can be queried to get the video URL in case of a failure.
Hi ,
I looked at it but it doesn’t provide the API for getting a video_url.
I am looking something like a REST api to get the video_url. The ruby code written above looks perfect. But I cannot use it since I use JS .
Any better solution is appreciated.
Thanks
Hi Pinky,
Ya, it doesn’t look like they provide an API for getting video_url. But I see they have some methods to get the session objects, so you may need to end up writing some wrapper around it to get the video_url. In our above Python code also we use session details to get the video_url.
I couldn’t find any other better solutions.
Thanks
Hi Avinash ,
Thank you very much for the response. Also , your python code does exactly what I want to. But I use Javascript and I am not familiar with Python. However will try with the node-browsestack package.
Thanks
Pinky