Companies are going to want to query their own internal documents – especially with the rise of LLMs and improvements in AI. Qxf2 has already heard of several CEOs that want to use AI/ML models to glean insights from internal knowledge stores. What does this mean for a tester? Well, you can expect to test such systems in the coming years. We could treat these applications are black boxes and tackle the testing with our current tool belt. However, understanding even little a bit of what goes under the hood of such systems will help. One, we can participate actively in the technical discussions. Two, our testing stands out from other testers who are not particularly pushing themselves to learn new perspectives. Three, we will be in a better position to keep up with advances in this field.
In this post, I am going to share what I understand about querying internal documents using machine learning and AI models. This topic has a lot of jargon and technical concepts. I have tried my best to explain them in a (slightly inaccurate but) non-technical manner. This should help you get started with the topic.
Why this post?
This post reflects my desire to solve a problem I encountered. There was an issue we consistently encountered at my previous client: support constantly bombarding engineers with queries that could have easily been resolved by referring to the release notes or troubleshooting guides. This prompted me to consider an alternative approach. What if support could seek assistance from someone else, allowing engineers to focus on engineering a high-quality product? I decided to explore the potential of leveraging Large Language Models (LLMs) to solve this problem. After exploring several other tools, I ultimately found myself working with Retrieval Augmented Generation (RAG).
While I haven’t yet accomplished the task I originally set out for – to create a question-answering entity that responds to questions based on context acquired from a document (e.g., a release note) – I am determined to persist in my efforts. I will continue writing and use this post, along with potential future ones, as a documentation of my ongoing progress in exploring the realm of context-based question answering
A Beginner’s Walkthrough of RAG Architecture
Retrieval Augmented Generation (RAG), as the name implies, generates responses to questions by leveraging context retrieved from a document or dataset. When given an input question, RAG employs a retriever component to obtain additional context, leading to more relevant and accurate answers. This architecture proves beneficial in overcoming challenges associated with fine-tuning models for knowledge-based question answering.
In the subsequent sections of this post, you will find concise explanations of the components that enable RAG. But if you get nothing else out of this post, at least remember that the black box model you had is now actually 3 black boxes. One to ‘retrieve’ another to ‘augment’ and the third one to ‘generate’. As a tester, you can imagine that this slightly more complex mental model allows us to imagine more possibilities as to where errors can occur. This breakdown might also aid us when we are trying to identify classes of errors and isolate them better.
Tools of the trade:
In order to facilitate my exploration:
1. I selected a familiar context to work with: football. To achieve this, I opted to utilize the rony/soccer-dialogues dataset. Although this dataset is not directly related to the specific problem I aimed to solve, I intentionally chose it due to my extensive knowledge and understanding of football. This decision enabled me to engage with a subject matter that I was well-versed in.
2. I have utilized Hugging Face’s Transformers module to download and use a pretrained model
3. I have used the RAG-Sequence Model – facebook/rag-sequence-nq model
Environment setup:
The setup process involves the following steps:
#Install Torch using the command: pip install torch torchvision #Install Transformers using the command: pip install transformers #Install Datasets using the command: pip install datasets #Install Faiss using the command: pip install faiss-cpu |
Chill if you are not familiar with any of these. I picked them up as part of this work. Also, you can follow along with this post even if you are unfamiliar with these Python modules.
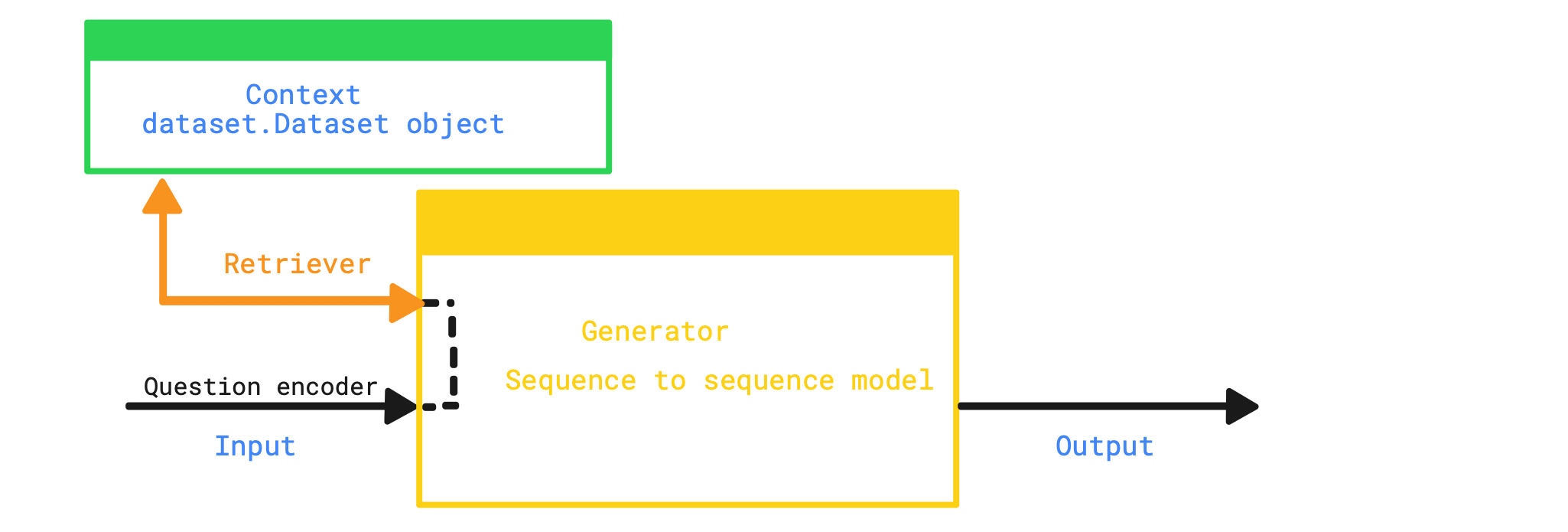
Unveiling the Logic:
The facebook/rag-sequence-nq model comprises three key components:
1. Question encoder
2. Retriever
3. Response generator
4. Output
In this section, I will provide an in-depth explanation of each of these components, accompanied by illustrative code examples.
1. Question encoder:
The Question encoder performs the task of encoding the question we want to pose to the LLM into a format that can be comprehended by the LLM.
from transformers import RagTokenizer tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq") question = "How old is Granit Xhaka" input_dict = tokenizer(question, return_tensors="pt") |
2. Retriever:
The Retriever component, a Dense Passage Retrieval (DPR) – a neural retriever(more information available in this paper), plays a crucial role in RAG. With its powerful search capabilities, DPR locates the most relevant context for the given question from a dataset, making it an essential element for acquiring context in RAG.
The dataset used for context retrieval must be a datasets.Datasets object with columns “title”, “text” and “embeddings”, and it must have a faiss index. Faiss is a library from Facebook that is good at figuring out similarity between two entities.
from transformers import RagRetriever from datasets import load_dataset ds = load_dataset(dataset_name, split='train[:100]') def transforms(examples): """ Transform dataset to be passed as an input to the RAG model """ inputs = {} inputs['text'] = examples['text'].replace('_',' ') inputs['embeddings'] = ctx_encoder(**ctx_tokenizer(inputs['text'], return_tensors="pt"))[0][0].numpy() inputs['title'] = 'soccer' return inputs ds = ds.map(transforms) # Add faiss index to the dataset, it is needed for DPR ds.add_faiss_index(column='embeddings') retriever = RagRetriever.from_pretrained("facebook/rag-sequence-nq", indexed_dataset=ds) |
3. Response generator
The Response generator is a sequence-to-sequence model that utilizes the context obtained from the Retriever component to generate output for the question posed.
from transformers import RagSequenceForGeneration model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq", retriever=retriever) generated = model.generate(input_ids=input_dict["input_ids"], max_new_tokens=50) print(f"{question}?") print(tokenizer.batch_decode(generated, skip_special_tokens=True)[0]) |
4. Output:
If you had played along, you can execute your script now. You should see something similar to the snippet below. I am showing you a trick to figure out if the answer is coming from the language model or the documents fed to it. You simply put something wrong or outdated in the dataset and query the model. If RAG is doing it’s job, it will return the incorrect/out-dated answer.
# Output How old is Granit Xhaka? 26 #If you are wondering why the output is 26, when Granit Xhaka is actually 30 years old(at the time of writing this post), this dataset is 4 years old. |
Visualizing the Details:
Putting it all together:
import os import torch from datasets import load_dataset from transformers import DPRContextEncoder, \ DPRContextEncoderTokenizer, \ RagTokenizer, \ RagRetriever, \ RagSequenceForGeneration, \ logging torch.set_grad_enabled(False) # Suppress Warnings logging.set_verbosity_error() # Initialize context encoder & decoder model ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base") ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base") dataset_name = "rony/soccer-dialogues" localfile_name = dataset_name.split('/')[-1] # load 100 rows from the dataset ds = load_dataset(dataset_name, split='train[:100]') def transforms(examples): """ Transform dataset to be passed as an input to the RAG model """ inputs = {} inputs['text'] = examples['text'].replace('_',' ') inputs['embeddings'] = ctx_encoder(**ctx_tokenizer(inputs['text'], return_tensors="pt"))[0][0].numpy() inputs['title'] = 'soccer' return inputs ds = ds.map(transforms) # Add faiss index to the dataset, it is needed for DPR ds.add_faiss_index(column='embeddings') # Initialize retriever and model rag_model = "facebook/rag-sequence-nq" tokenizer = RagTokenizer.from_pretrained(rag_model) retriever = RagRetriever.from_pretrained(rag_model, indexed_dataset=ds) model = RagSequenceForGeneration.from_pretrained(rag_model, retriever=retriever) # Generate output for questions question = "How old is Granit Xhaka" input_dict = tokenizer(question, return_tensors="pt") generated = model.generate(input_ids=input_dict["input_ids"], max_new_tokens=50) print(f"{question}?") print(tokenizer.batch_decode(generated, skip_special_tokens=True)[0]) |
This project is available on GitHub. You can find it here
Next steps:
With a functional prototype in hand, I am now committed to further exploration, aiming to gain a deeper understanding of the following aspects:
1. The inner workings of non-parametric memory generation models.
2. The utilization of DPR by RAG for retrieving relevant information.
3. Identifying effective methods for testing a RAG model.
Hire testers from Qxf2
Hire Qxf2 for our expertise in technical testing and problem-solving abilities. We go beyond standard test automation to tackle critical testing challenges, ensuring your team can iterate quickly and deliver high-quality software. Let us help you optimize your testing practices and improve overall product quality.
My expertise lies in engineering high-quality software. I began my career as a manual tester at Cognizant Technology Solutions, where I worked on a healthcare project. However, due to personal reasons, I eventually left CTS and tried my hand at freelancing as a trainer. During this time, I mentored aspiring engineers on employability skills. As a hobby, I enjoyed exploring various applications and always sought out testing jobs that offered a good balance of exploratory, scripted, and automated testing.
In 2015, I joined Qxf2 and was introduced to Python, my first programming language. Over the years, I have also had the opportunity to learn other languages like JavaScript and Shell scripting (if it can be called a language at all). Despite this exposure, Python remains my favorite language due to its simplicity and the extensive support it offers for libraries.
Lately, I have been exploring machine learning, JavaScript testing frameworks, and mobile automation. I’m focused on gaining hands-on experience in these areas and sharing what I learn to support and contribute to the testing community.
In my free time, I like to watch football (I support Arsenal Football Club), play football myself, and read books.

