At Qxf2, we have always been curious on how to test and validate the datasets and models. A good machine learning team should continuously monitor the model to identify any changes in model performance. You need to be confident that your models are accurate, reliable, and fair. Deepchecks can help you achieve this by providing a comprehensive set of tools for validating your models and datasets. Deepchecks is a Python open-source tool used for testing and validation of machine learning models. This post outlines few steps required for thorough testing and validation of both machine learning models and datasets using Deepchecks.
Setup and Installation
Installing Deepchecks For NLP is pretty straight forward.
pip install -U deepchecks[nlp] |
About our Dataset and Model
Our dataset PTO_messages.csv is a collection of text messages for Paid Time Off (PTO) and non-PTO. The labels denote binary classification, with 0 representing not PTO and 1 representing PTO-related messages. You can find our dataset here
data.head() |

For the purpose of this blog post, I have done few modifications to our Python script PTO_detector.py to train on RandomForestClassifier model to generate outputs for various checks.
Note: This script PTO_detector.py was originally trained on LinearSVC model to classify the PTO or non-PTO.
Deepchecks Suites
Deepchecks is bundled with a set of pre-built suites that can be used to run a set of checks on your data. There are 3 suites, the data integrity suite, the train test validation suite and the model evaluation suite. You can also run all the checks at once using the full_suite. These check sets help you make sure your data and models are reliable and accurate.
Data Integrity
This is a check for data integrity that examines the correctness of text formatting. Its purpose is to verify if the dataset is both accurate and complete.
Train Test Validation
The train-test validation suite is used to compare two datasets: the training dataset and the testing dataset. It ensures that the division between these two sets of data is accurate.
Model Evaluation
The model evaluation suite runs after a training the model and requires model predictions. This check is to evaluate the performance of a model.
Deepchecks data types
Deepcheck supports different data types commonly used in Machine Learning.
In this post, I will be testing our Text classification model, focusing on NLP checks and suites that are relevant for this particular scenario. Please note that our dataset is designed for binary classification data with “Text” and “Labels”.
Implementing Deepchecks NLP
Deepchecks NLP offers various data checks, such as data integrity and drift checks, which can work on any NLP task.
To execute deepchecks for NLP, you’ll need to create a TextData Object for both your training and testing data. The TextData Object serves as a container for your textual data, associated labels, and relevant metadata for NLP tasks.
Firstly, import the TextData from Deepchecks
from deepchecks.nlp import TextData |
You’ll need to create a TextData object for the train and test data as shown below
train = TextData(X_train, label=y_train, task_type='text_classification') test = TextData(X_test, label=y_test, task_type='text_classification') |
The arguments required by the TextData is the train data, label, task_type and metadata(Optional). In the above code, the train object is created using training data (X_train) and their corresponding labels (y_train), the test object is created using testing data (X_test) and their corresponding labels (y_test) with the specified task type.
Data Integrity Checks
Next, now you can run integrity suite on this TextData object:
from deepchecks.nlp.suites import data_integrity data_integrity_suite = data_integrity() data_integrity_suite.run(train, test) |
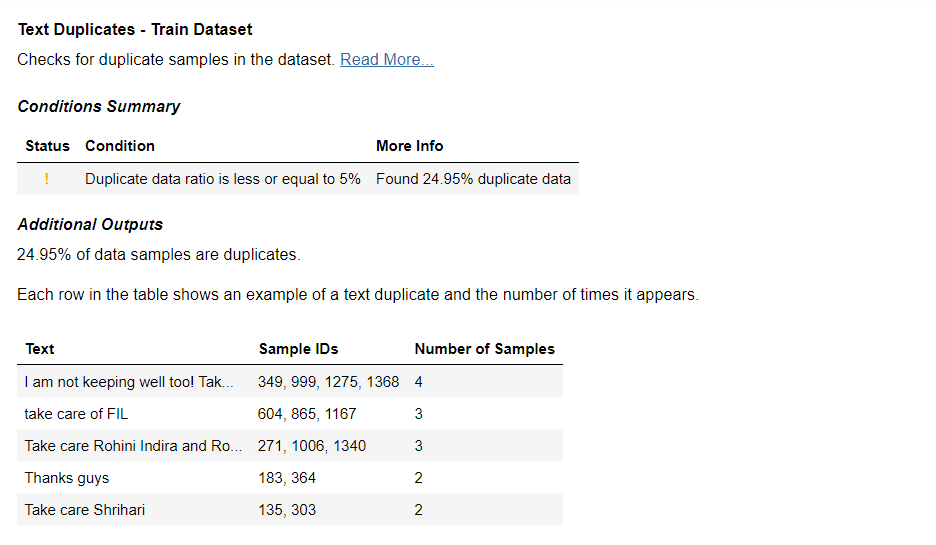
Deepchecks conducts data checks and outputs pass or fail based on default conditions. Now, let’s deep dive into the summary for more understanding. The summary displays few passed and failed results as shown below. Our focus will be on analysing the failed conditions and figure out the issues. Note: For this blog purpose, the process of cleaning data has been disabled in order to showcase the presence of unknown tokens within the output.
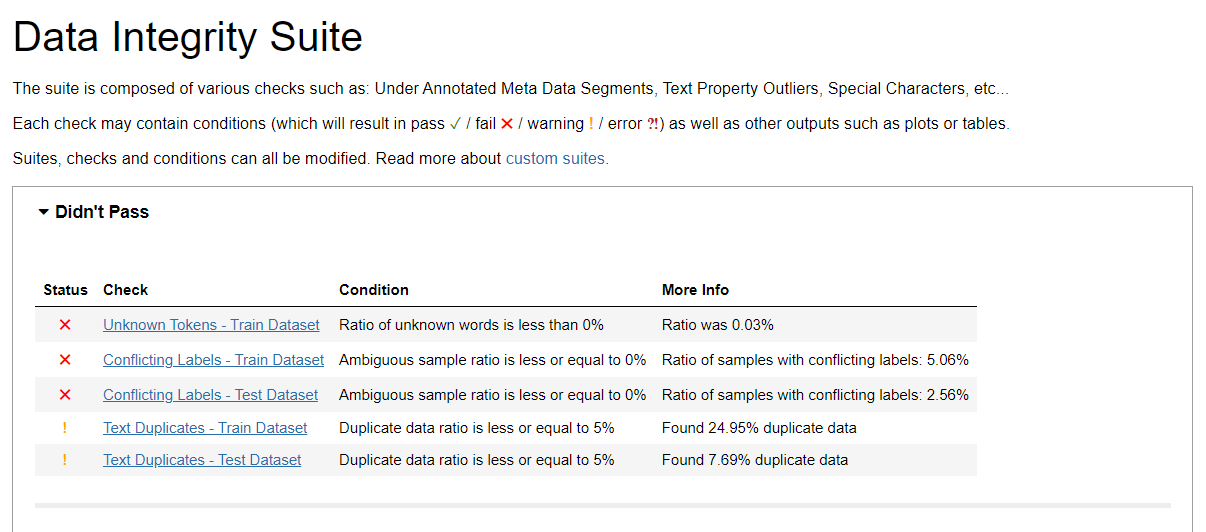
Unknown Tokens
Unknown tokens are words, special characters, or emojis in the text that are not recognized by model’s tokenizer. The initial check (marked with the x in Didn’t Pass) tells us that the samples contains unexpected tokens in the dataset. Since the actual ratio is 0.03% and the check expects it to be 0%, the check has failed. This low ratio indicates that most of the text in the training dataset is already recognized and processed effectively by the tokenizer. In the instances of high ratio, you can simply pre-process the data or update your tokenizer to minimize the occurrence of unknown tokens.
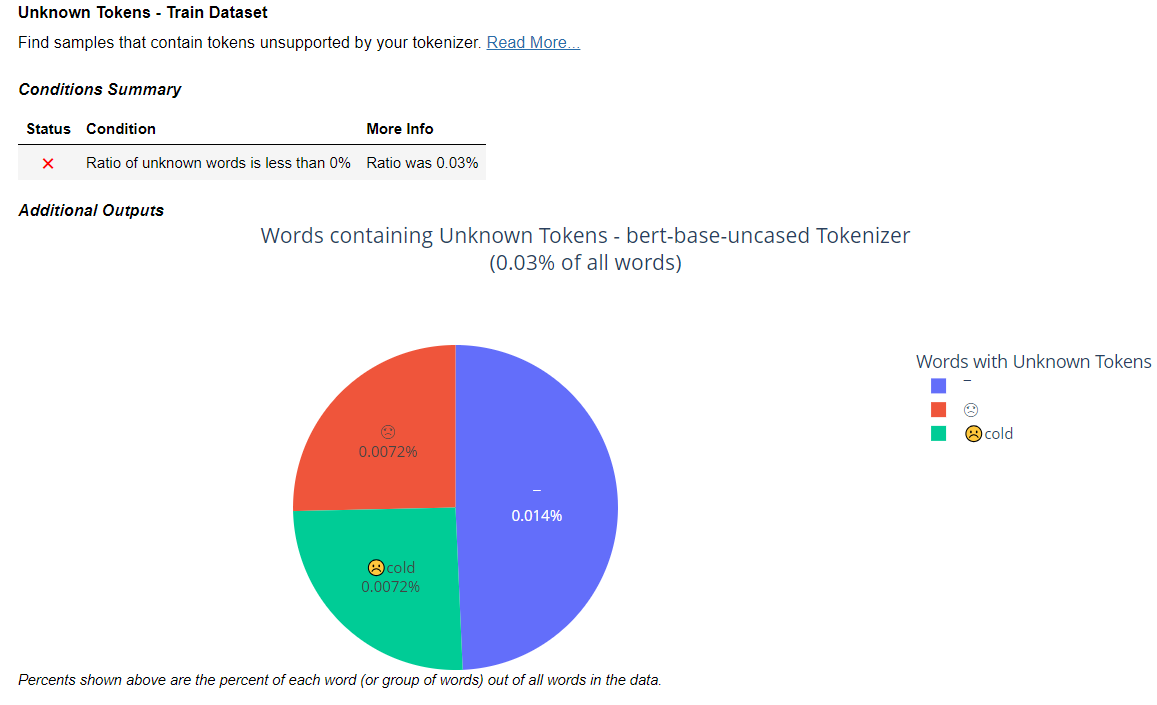
Conflicting Labels – Train Dataset and Text Dataset
Train Dataset and Text Dataset – The second check identifies identical or nearly identical samples in the dataset that have different labels. This failed case indicates the presence of conflicting labels in the dataset. This insight is valuable as it points out inconsistencies in labelling to ensure accurate model training and evaluation. The check has not passed because the percentage of samples with inconsistent labels in train dataset is 5.06%, while the Test data contains 2.56%. This exceeds the defined threshold of 0%, indicating that there are cases where the same sample possesses different labels.
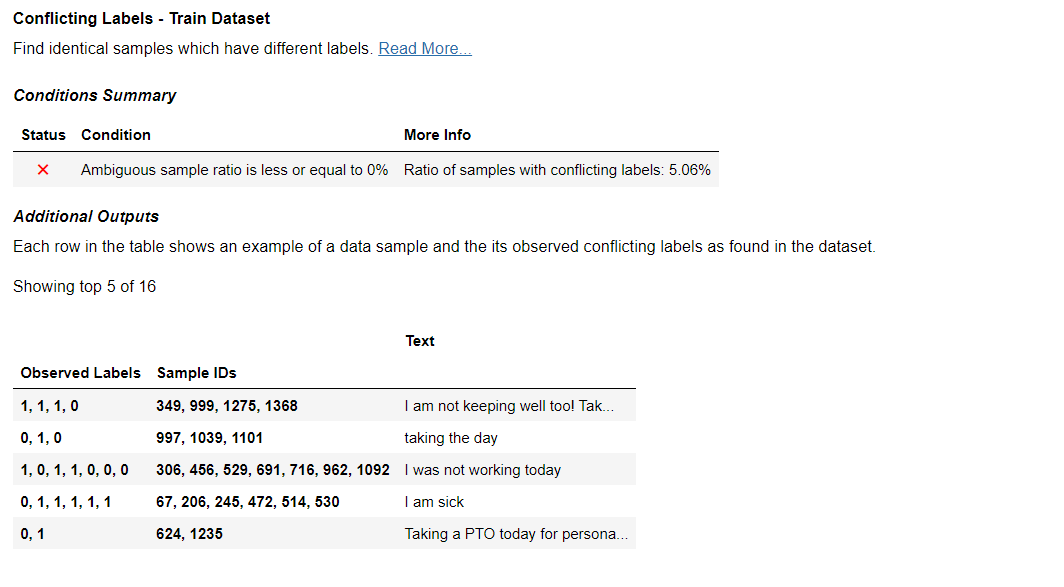
Text Duplicates – Train Dataset and Text Dataset
This check examines the presence of duplicate sample in both Train and Test sets. Our output shows that the Train data contains 24.95% duplicate data, while the Test data contains 7.69% duplicate data. These percentages exceed the threshold of 5%, alarming potential data redundancy that needs to be fixed.
Similarly you can conduct checks for Text Property Outliers, Property Label Correlation, Special Characters, Under Annotated Metadata Segments etc checks. Please refer Deepchecks NLP documentation for more details. By rectifying these issues, you enhance the quality of the data.
Train Test Evaluation
Once you are confident that your data is all good to be trained, next step is to validate the split and compare train and test dataset.
from deepchecks.nlp.suites import train_test_validation train_test_validation().run(train, test) |
Train Test Samples Mix
The output shows one failed and one passed condition in our case. This check tells us about the percentage of test data samples that also appear in the training data. The goal here is to maintain a balance and avoiding an overlap between the two sets. In our case, about 29.49% of the test data samples also appear in our training data. The desired percentage is lower than 5% and we are above that threshold. This information is very valuable for fine tuning our dataset and model’s evaluation.
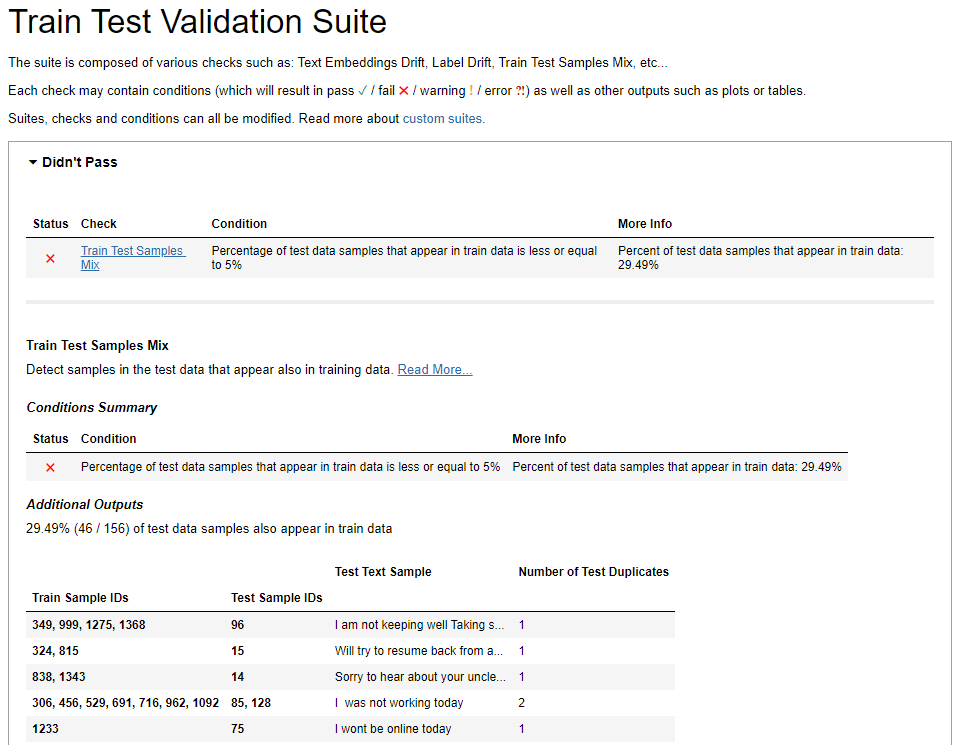
Upon closer examination specific test samples were found to have corresponding instances within the training set(46 out of 156). To address this you can apply different split techniques suitable for your requirements to reduce the data overlap.
Label Drift
We also have a passed status for the “Label Drift” check. The Label Drift check acts as a measure to gauge the dissimilarity between the distributions of labels in the train and test datasets. It calculates the difference in label distributions between these datasets. The “Passed” status signifies that the label drift is within an acceptable range, with a minimal score of 0.15.
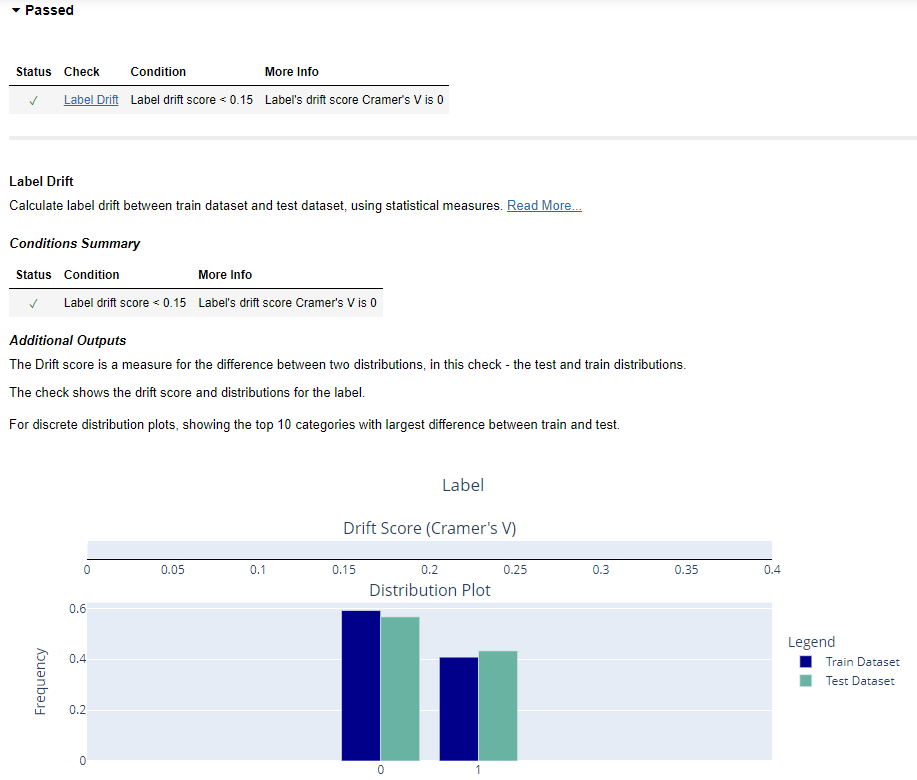
This check also provides insights into the distributions, showing the top 10 categories with the most significant differences between the two datasets. Similarly, you an conduct Embedding Drift, NLP Property Drift checks. Please refer Deepchecks NLP documentation for more details
Model Evaluation
The model evaluation suite, is designed to be run after a model has been trained and requires model predictions and probabilities which can be supplied via the arguments in the run function.
from deepchecks.nlp.suites import model_evaluation model_evaluation().run(train, test, train_predictions=train_preds, test_predictions=test_preds, train_probabilities=train_probs, test_probabilities=test_probs) |
Train Test Performance
The condition “Train Test Performance” failed in the output. The train test degradation score is a measure of how much a model’s performance drops when moving from the training dataset to the testing dataset. It’s an important metric to evaluate how well a model performs on the unseen data.
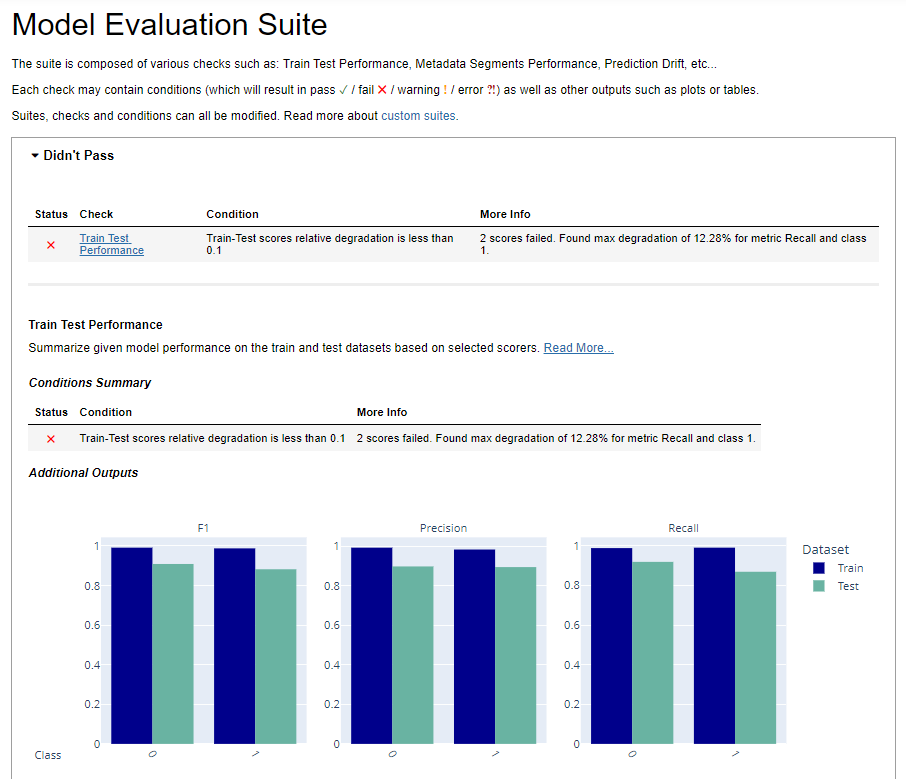
The output also highlights that there are 2 scores that failed this degradation test. The most significant degradation observed is for the “Recall” metric, specifically for class 1 with a maximum degradation of 12.28%. It signifies a notable drop in the model’s ability to correctly identify instances belonging to class 1 when applied to new or unseen data. This could imply that the model is not maintaining consistent performance levels across training and testing data.
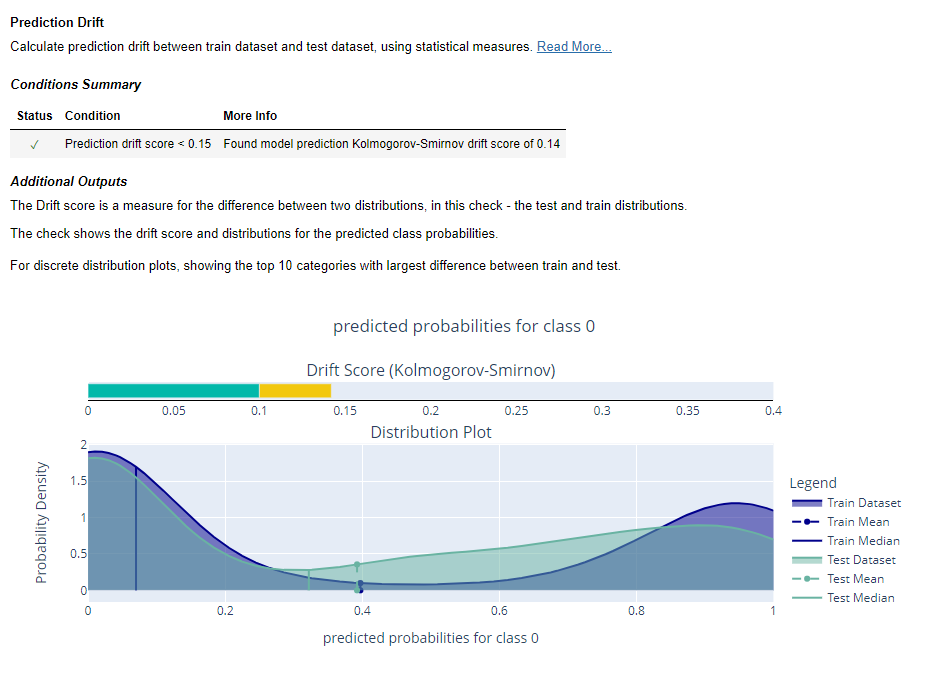
Prediction Drift
The condition for “Prediction Drift” passed in the output. It is indicating the outcome of monitoring the model for prediction drift using the Kolmogorov-Smirnov (KS) drift score. The KS drift score reported is 0.14. Even though the KS drift score of 0.14 is slightly lower than the specified threshold 0.15, it is important to analyze the source of this drift. Compare the distribution of predictions at various time points to pinpoint when the drift started occurring. Consider retraining or fine-tuning the model to ensure that the model remains effective and reliable in its predictions over time.
Full Suite
Deepchecks gives a quick overview of your model and data with Full Suite that includes many of the implemented checks. full_suite is a collection of the prebuilt checks.
To import the full_suite method, use the code below
from deepchecks.nlp.suites import full_suite suite = full_suite() suite.run(train_dataset=train, test_dataset=test, with_display=True, train_predictions=train_preds, test_predictions=test_preds, train_probabilities=train_probs, test_probabilities=test_probs) |
This will perform full checks on the dataset objects and the model and generates a consolidated output with Passed/Didn’t Pass.
You can find the final code here.
Using Deepchecks, helps us check and fine tune our models and data. It’s user-friendly and offers different tests to catch issues early, making our models work better. Happy Testing!!
References
1. Deepchecks Documentation
2. Deepchecks NLP: ML Validation for Text Made Easy
3. High-standard ML validation with Deepchecks
Hire technical testers from Qxf2
Qxf2 offers valuable expertise in testing Machine Learning projects. Our team goes beyond traditional QA to ensure data quality, model accuracy, and system robustness. With us, you’ll have skilled testers who understand the nuances of ML and can enhance the reliability of your projects. Get in touch with us!

I am an experienced engineer who has worked with top IT firms in India, gaining valuable expertise in software development and testing. My journey in QA began at Dell, where I focused on the manufacturing domain. This experience provided me with a strong foundation in quality assurance practices and processes.
I joined Qxf2 in 2016, where I continued to refine my skills, enhancing my proficiency in Python. I also expanded my skill set to include JavaScript, gaining hands-on experience and even build frameworks from scratch using TestCafe. Throughout my journey at Qxf2, I have had the opportunity to work on diverse technologies and platforms which includes working on powerful data validation framework like Great Expectations, AI tools like Whisper AI, and developed expertise in various web scraping techniques. I recently started exploring Rust. I enjoy working with variety of tools and sharing my experiences through blogging.
My interests are vegetable gardening using organic methods, listening to music and reading books.

